# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在用 AI 做项目,经常会碰到这种尴尬的情况:
写代码,它喜欢乱造轮子,能用十行解决的事,非要写一大坨。
做页面,它能把功能搭出来,但审美一言难尽。
抓数据,它很多网页抓不全、抓不准,甚至直接没权限。
不是不会做,而是做得太糙了,完全不注意工程细节。
针对上面这些问题,我整理了三个开源项目,帮助你的 AI 更准确地实现需求。
这个项目,目前在 GitHub 上已经 6.8 万多 Star 了,能让你的 AI 少写一半的代码。
它叫 Ponytail,是一个可以放进 Agent 里的插件。
项目图标是一个扎着马尾辫、戴着眼镜的资深程序员形象,意为此项目对修改屎山代码很有经验。

Ponytail 的思路不是事后帮你压缩代码,而是在 AI 动手之前,先给它套上一层“少写代码”的纪律。
你只是告诉 AI 代码要写短一点。
Ponytail 则是让它在动手前先作判断:
.....
实在不行,再写最小可用实现。
它不是让 AI 为了短而短,而是让 AI 先从“不写代码”开始思考。
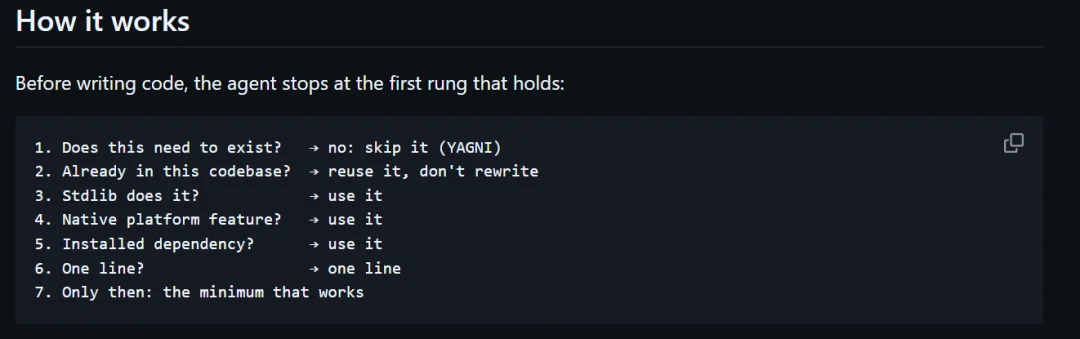
比如做一个日期选择器,能力弱一点的 Agent 可能会装库、写 wrapper、加样式、处理一堆边界情况。
Ponytail 会先问 Agent 浏览器不是已经有 <input type="date"> 吗?
然后直接原生能力解决,决不会多写一行代码。
在 Agent 不同运行阶段,它都会自动把规则塞进去。
比如,在会话刚开始,它会通过 SessionStart 加载规则。
如果主 Agent 又启动了子 Agent,它还会通过 SubagentStart 把同一套规则继续传给子 Agent,避免子 Agent 乱造轮子的情况。
这就很舒服,因为它贯穿到整个 Agent 工作流里,不用你一直操心。
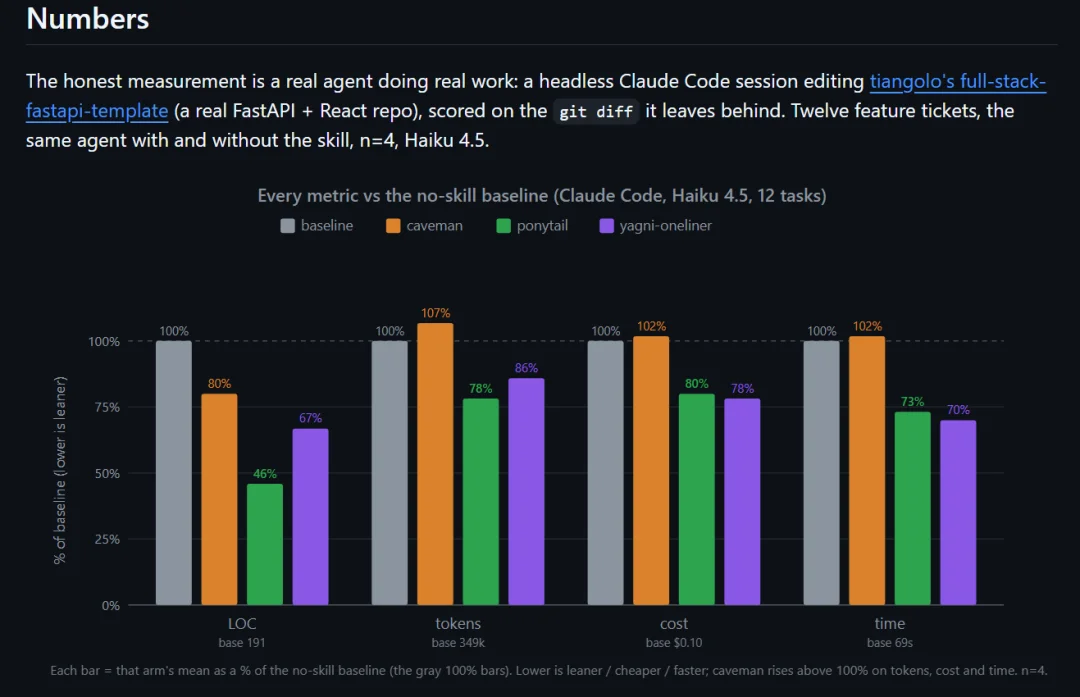
作者在一个真实的 FastAPI + React 开源项目里,用 ponytail 作了实测,模型用的是 Haiku 4.5。
在前端这种最容易过度工程化的任务里,Ponytail 的效果非常强。
当然,它也不是所有任务都能砍很多。
像后端 CRUD 这种本来就没太多水分的任务,各组差距就不大。
最后汇总下来,在 12 个真实任务里,Ponytail 相比普通 Claude Code,平均减少了 54% 的新增代码行数,token 降了 22%,成本降了 20%,耗时也少了 27%。
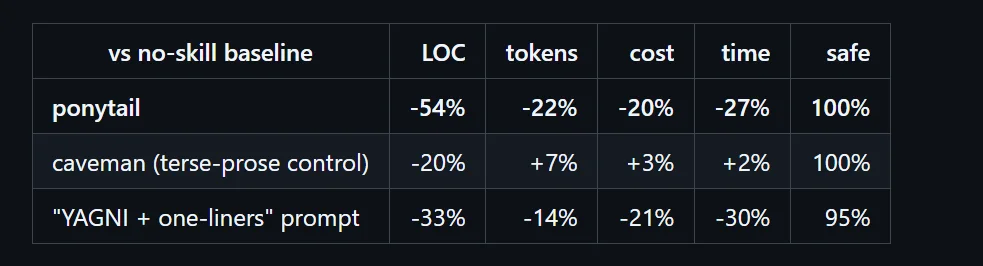
安全性方面,Ponytail 的通过率是 100%。
插件支持 Claude Code、Codex、OpenCode 等主流 AI 编程工具。
安装到 Claude Code ,只需执行下面两行命令即可安装好。
/pluginmarketplaceaddDietrichGebert/ponytail/plugininstallponytail@ponytail
另外插件还提供了几个模式,lite 轻量、full 完整、ultra 激进,不想用了直接 off 关掉。
项目链接:
https://github.com/DietrichGebert/ponytail
这个项目只需要一行命令,就可以1:1复刻网页。
普通 AI 克隆网页,很多时候只是看截图,然后凭感觉猜颜色、字体、间距和布局。所以做出来的页面远看像,近看全是问题。
而这个项目是一个网页逆向工程系统,会把浏览器里的每个细节都尽量转化成可复现的前端代码。
它的工作流是这样的:
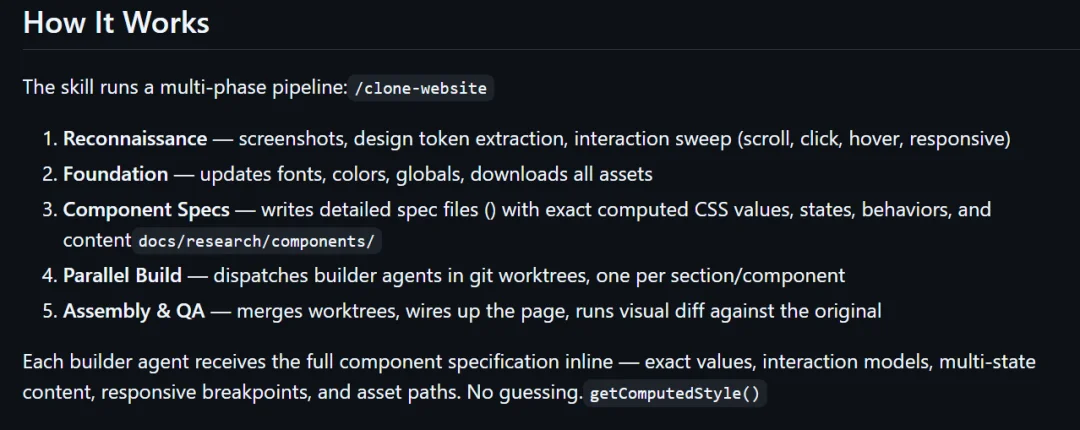
首先,它会先让 AI 通过浏览器真正打开目标网站,对页面做一轮全域采集,通过 getComputedStyle() 直接读取浏览器里的真实计算值。
比如网页里具体的颜色的数值是多少,字体是什么,间距、圆角、阴影具体参数是什么。
拿到这些设计 Token 之后,AI 才会开始先搭底座,全局 CSS、Tailwind 配置、静态资源都会先对齐原站。
接下来,它会把整个页面拆成一个个组件。
每个组件都会先生成一份规格书,写清楚这个区块的结构、响应式变化和交互状态。
之后,它再让多个 builder agent 并行施工。每个 Agent 负责一个组件,并且放在独立的 git worktree 里开发。
这样导航栏、Hero 区、页脚可以同时做,互不干扰。
最后,AI 把这些组件合并回主项目,拼成完整页面。
下面是作者给到的实测视频:
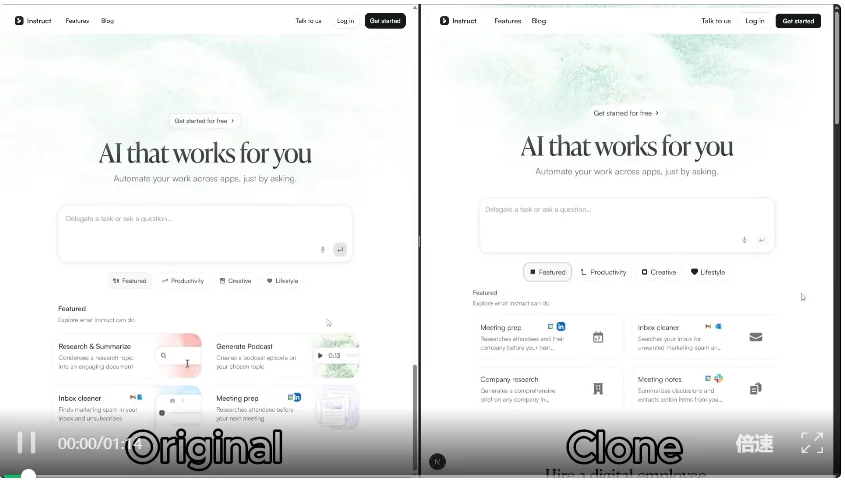
这比让一个 AI 从头到尾写完整页面稳定很多。
因为前端页面本来就是模块化的,拆成区块以后,Agent 更容易对齐原站,也更容易做视觉校正。
当然,这个项目更适合用在你自己的网站迁移、学习优秀页面结构这些场景。
不适合拿来直接搬别人的商业网站上线。
安装方面,这个项目官方不建议直接 clone 原仓库,而是先在 GitHub 页面点击 Use this template,创建一份属于你自己的项目。
然后把你自己的仓库 clone 到本地:
gitclonehttps://github.com/YOUR-USERNAME/YOUR-NEW-REPOSITORY.gitcdYOUR-NEW-REPOSITORY
接着启动 Claude Code,输入:
/clone-website<目标网站URL>
接下来,AI 就会打开目标网页,采集页面结构、提取设计 Token 和资源,然后开始重建这个网站。
项目要求 Node.js 24+,官方推荐 Claude Code,但 Codex CLI、Cursor、Windsurf、Gemini CLI 等 AI 编程工具也支持。
项目链接:
https://github.com/JCodesMore/ai-website-cloner-template
这个项目能把任何网页,变成 AI 能直接读取的结构化数据。
你给它一个 URL,它可以输出:
不只是抓单页,它还能爬整个网站、解析本地文件、做 arXiv 论文搜索、搜索 GitHub 仓库信息。
而且, Firecrawl 主推无 Key 模式,不用配环境、申请密钥,直接就能用。
Firecrawl 的能力有三层:
map 把站内 URL 列出来。以前 Agent 读网页,要自己处理搜索和解析。
现在 Firecrawl 先把这些脏活做掉,最后交给 AI 的就是干净的数据。
这个项目已经不是一个小众工具了。
它是 GitHub 全站 Top 100 级别的开源仓库,目前已经有 130K+ Star。
官方数据显示,有 15 万多家公司在用 Firecrawl,其中包括 Apple、Canva、Lovable、Stanford、Zapier、Replit 这些团队。
安装 Firecrawl 只需一行命令:
npx-yfirecrawl-cli@latestinit--all--browser
它支持 Claude Code、OpenCode、Cursor、Windsurf、Codex CLI、Gemini CLI、Antigravity。
项目链接:
https://github.com/firecrawl
少写没必要的代码,做出更准的页面,拿到更干净的数据,AI 做项目的可用性就会高很多。
这期就先分享这三个项目,都是我觉得真正能改善 AI 工作流的开源项目。
文章来自于"JackCui",作者 "JackCui"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
