# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
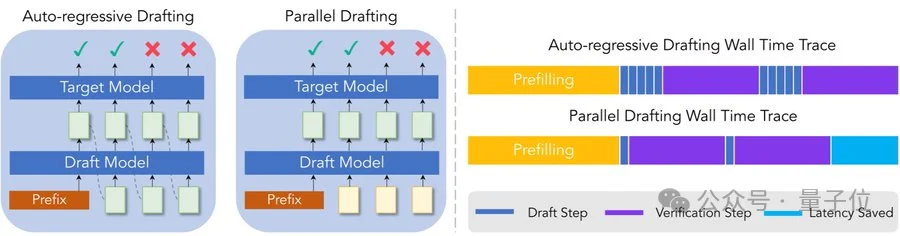
梁文锋署名的DeepSeek新论文DSpark你可能刷到过了——
单用户速度提升85%、高并发场景有效吞吐翻4倍。
但你真的看懂了吗?

别急,有人替你拆解了一遍。
Fireworks AI的联合创始人兼CTO、PyTorch核心维护者Dmytro Dzhulgakov将整篇论文梳理成了10个概念,从最底层的GPU访存特性讲到最上层的在线自适应调度。
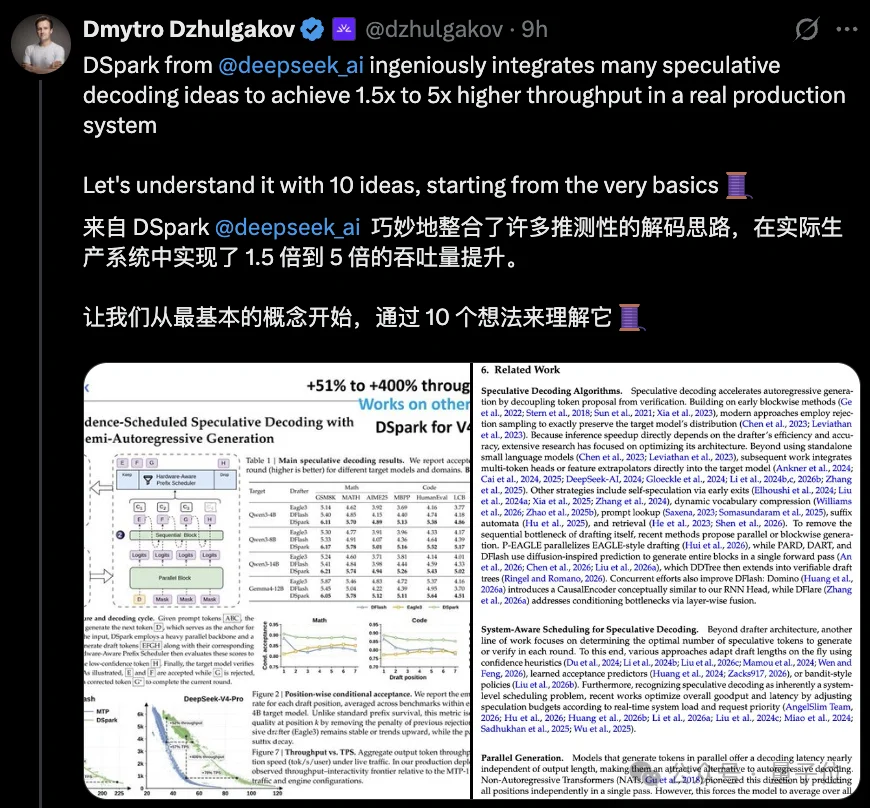
他认为:
DeepSeek这套方案真正的精髓在于系统工程和模型协同设计。
相关基础思路前人已有提出,难能可贵的是其将各类技术融合为一套自适应完整系统,实现了端到端的显著性能优化。
下面我们就顺着这10个概念过一遍DSpark。
想要搞懂大模型各类推理加速技术,首先要理解GPU一个非常特殊的运行特性:
让GPU同时解码10个token,其实只比解码1个token慢一点点。
卡帕西曾经讲过,原因在于大模型推理的瓶颈不是浮点运算,而是显存带宽,GPU大部分时间花在把模型权重从显存搬到计算核心上。
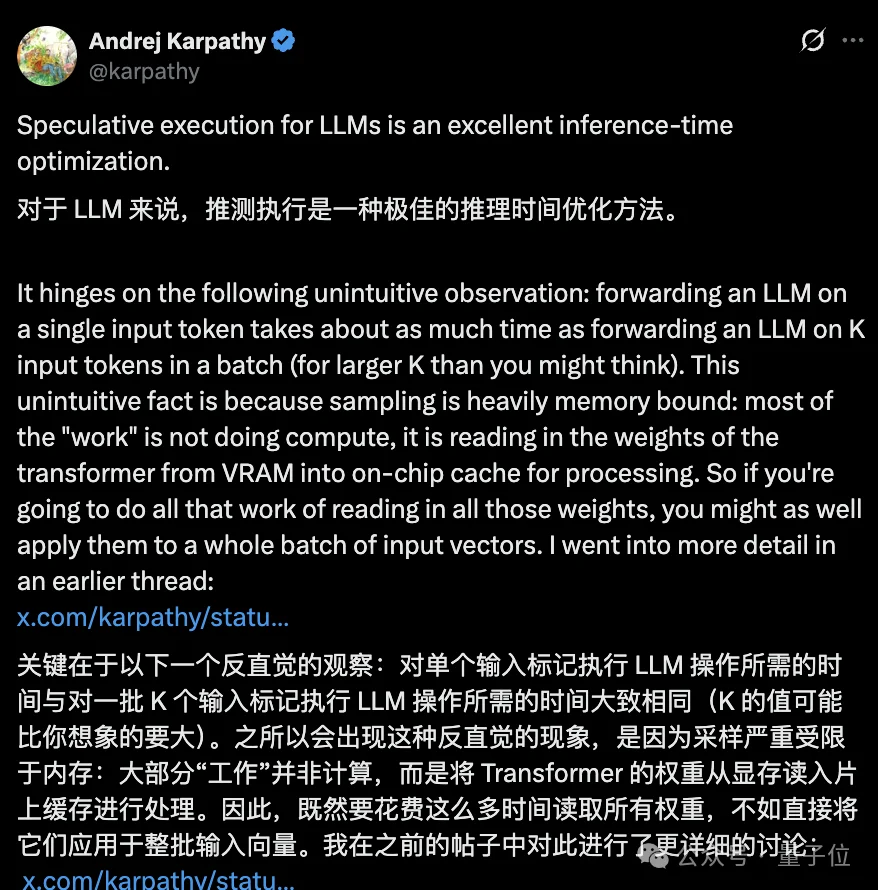
搬一次也是搬,搬十次也是搬,既然权重已经加载到了缓存里,不如一次搬运、干十件事。
这就是连续批处理:把多个请求的token塞进同一个batch,让每一次显存读取都物尽其用。
理解了这一点,就明白为什么推测解码能奏效,它的本质就是把“猜出来的多个候选token”打包成一个batch送给大模型验证,而验证batch的成本,远低于逐个生成的成本。
大模型生成是自回归的,第N+1个token依赖第N个token的结果,没法直接并行。
但有一种绕路的办法,如果你能「猜」出接下来几个token是什么,就可以把猜出来的候选序列一次性喂给大模型做批量验证。
验证是通过拒绝采样,系统逐个检查候选token,接受最长的正确前缀,在第一个分歧点重新采样一个token。
这套规则在数学上保证输出分布与原模型完全一致,没有任何质量损失。
所以推测解码的本质是用“猜+验”替代“逐字生成”。
猜的环节用小模型可以很快,验的环节进行批量验证可以很高效,所以最终每一步都能往前跳好几个token。
DSpark就是这个方向上的最新进展。
那怎么猜呢?
最直接的方案是拿一个小模型当“草稿器”。
比如用Qwen 0.8B给Qwen 397B探路,小模型跑得快,把候选序列生成好,大模型只需要做一次前向传播来验证。
通过了就全收,没通过就从分歧点重新来。
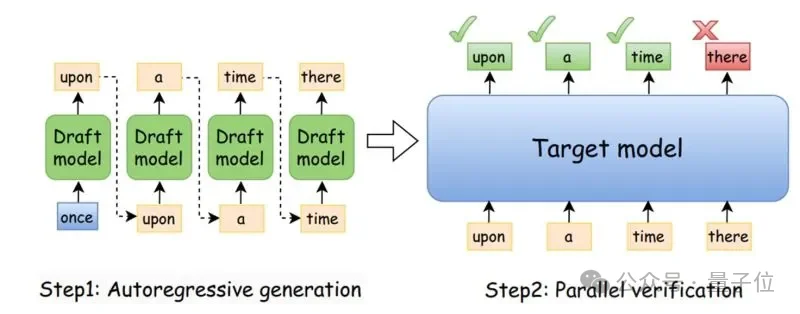
这个设计把推理过程分成了两个角色,速度型选手草稿器负责猜,力量型选手目标模型负责判。
二者配合得好,整体速度就能大幅提升。
但要想配合得好,背后需要权衡大量工程取舍,接下来几个概念就是在讲这些取舍。
草稿模型引入了额外开销。
如果草稿器自己跑得太慢,或者一次猜了16个token但只有前3个被接受,那这笔帐就不划算了。
论文给出了一个核心公式来描述实际延迟:
每个token的耗时= (草稿耗时+验证耗时) /被接受的token数τ。
在这个理论下,加速只有三条路可以走,降低草稿耗时(猜得更快)、提高τ(猜得更准)、减少验证浪费(验得更聪明)。
猜得越多不一定越好,因为如果多猜的token大概率被拒绝,它们只会白白占用验证batch的宝贵算力。
所以DSpark的整篇论文,可以理解为同时拉动这三个杠杆的一次系统性尝试。
第一根杠杆,就是优化草稿模型本身的构造。
草稿模型不用从零训一个完整的小模型,有一种更聪明的做法是直接把目标模型最后一层的隐藏状态拿过来,在上面加1–2层Transformer头当草稿器。
这就是Eagle系列和MTP(Multi-Token Prediction)的思路。
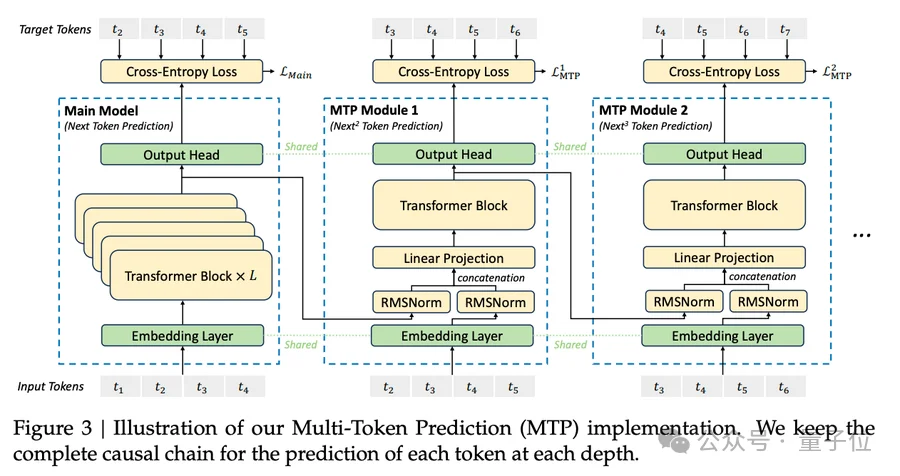
好处有两个,一个是快,草稿器只有1–2层,计算量极低;
二是准,因为它直接吃的是目标模型的内部理解,也就是最后一层激活值,等于站在巨人肩膀上猜下一步,比从头用小模型独立推理要靠谱得多。
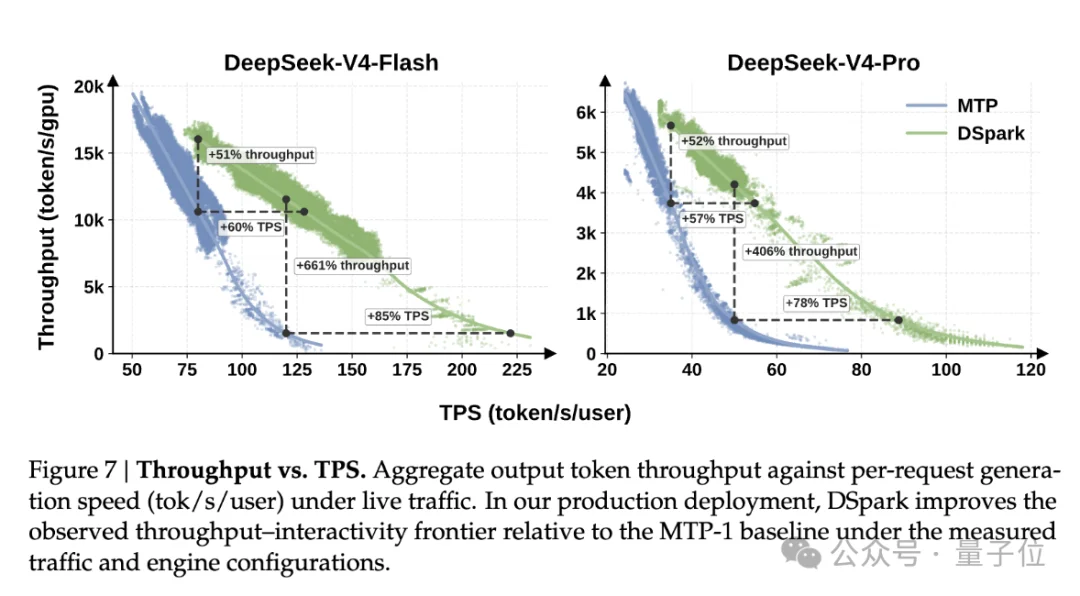
DeepSeek-V3就已经在用MTP做单token推测(MTP-1)。
DSpark论文中所有的加速数字都是跟MTP-1这个基线对比的,也就是说,60%–85%的速度提升是在已经优化过的基础上再叠加的。
但Eagle/MTP的问题在于,要生成N个候选token,就得跑N步,第2个token依赖第1个的输出,第3个依赖第2个……串行的链条没法打破。
DFlash的思路是借鉴扩散模型的做法,一次前向传播就把全部N个候选位置同时产出。

速度确实快,但代价是各位置之间没有依赖关系。开头几个token可能很准,因为上下文信息充足,但越往后越拉胯。
论文管这个问题叫多模态碰撞。
举个例子,位置1采样出“of”,位置2独立采样出“problem”,各自看概率都合理,拼在一起就变成了“of problem”这种不通顺的组合。
位置越靠后,这种跑偏的概率越大,接受率急剧下滑。
这就是所谓的后缀衰减(suffix decay),也是纯并行方案在实际部署中加速效果打折的主因。
DSpark的核心创新,用一句话说清就是把并行和串行拼在一起,各取所长。
具体做法分两步。第一步,用DFlash的并行骨干网络一口气生成所有位置的基础logits,这一步负责速度。
第二步,用一个轻量级的顺序头从前往后逐个位置注入前缀依赖偏置,这一步负责修正后缀衰减。
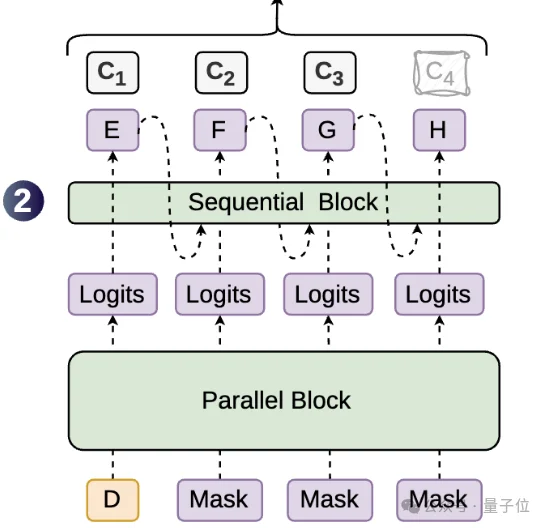
用上面的例子来看,效果是:
位置1采样出“of”之后,顺序头会把位置2的概率分布往“course”方向推,同时压低“problem”的概率。
并行骨干保证了整体速度不拖后腿,顺序头保证了后半段的接受率不崩盘。
在论文的离线测试中,DSpark的平均接受长度比Eagle3高26%–31%,比DFlash高16%–18%。
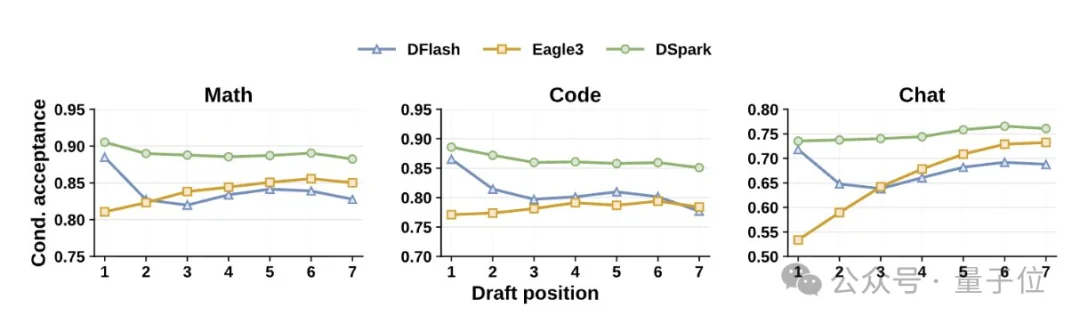
两层DSpark甚至打得过五层DFlash。
既然第二步要加一个顺序头,那它的成本不就把第一步省下来的时间又吃回去了吗?
DSpark的回答是:不会,因为并行骨干已经把上下文信息编码好了,串行步骤不需要再做完整的注意力计算,只需要做极轻量的修正。
默认方案是一个马尔可夫头,它只看前一个token就决定当前位置的修正方向,通过低秩分解(rank 256),即使词表有十几万个token,计算成本也几乎可以忽略。
实测数据就很能说明问题,草稿长度从4扩展到16,每轮额外增加的延迟只有0.2%–1.3%,但接受长度最高提升了30%。
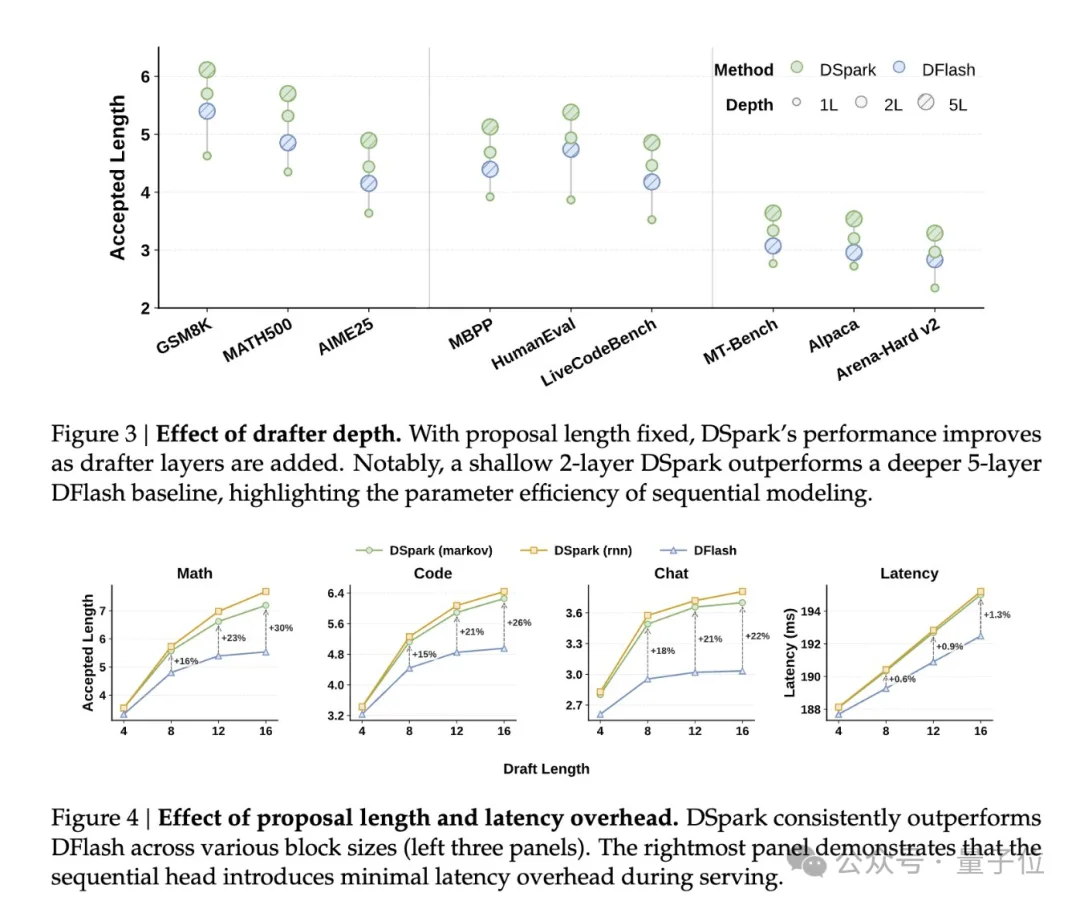
论文里还提供了一个 RNN 头的可选方案,可以追踪整个草稿块的前缀信息,但实际增益有限,所以默认没有开启。

这也体现了DSpark的工程审美,不是越复杂越好,而是找到成本和收益的最优折中。
那每次应该猜几个token呢?这个问题没有固定答案。
首先,不同类型的请求天然不同。
代码生成的可预测性高(语法模式强),草稿器猜8–16个token可能都能过审;开放式闲聊不确定性大,猜4个就可能翻车。
其次,服务器的实时负载也在变化。
GPU空闲时,多猜几个token没什么额外成本,反正算力闲着也是闲着;高并发时,每一块验证batch的算力都很金贵,不该浪费在大概率被拒绝的尾部token上。
于是DSpark用一个置信度头给每个草稿位置打分,预估它在验证中存活的概率。

这套方案会预先测算GPU在各类批次尺寸下的硬件吞吐数据,生成吞吐量参考曲线,再依据曲线结果为每条请求动态匹配最优验证长度。
整套调度逻辑完全在GPU内部执行,无需CPU参与,虽然实现门槛极高,但该方案已经落地了。

接下来,就是最后一块拼图,在线草稿置信度校准。
置信度头的思路很好,但有一个实际问题是“神经网络天生过度自信”。
它觉得自己猜的每个token都对,这就会导致原始置信度评分不可靠,该停的时候不停,该放手的时候死撑。
如果直接用模型输出的概率设阈值,系统表现会跑偏。
DSpark 的做法是在运行时持续观察草稿器的实际表现。
论文中使用顺序温度缩放做后处理校准,把预期校准误差从3%–8%压到了约1%。
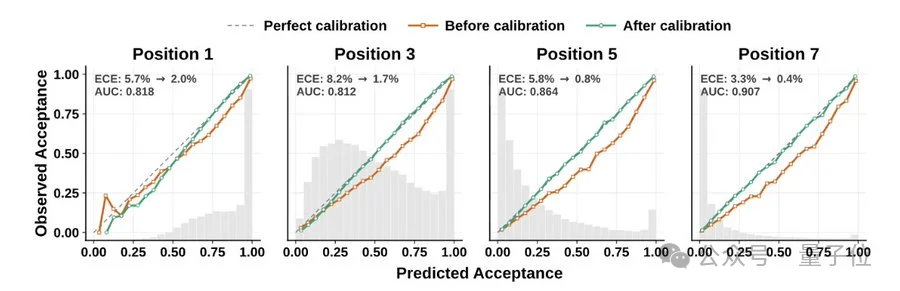
更关键的是,这个校准过程是在线的,系统边跑边调,根据当前工作负载的实际接受率动态修正阈值。
代码任务跑多了,它就学会对代码草稿更宽容;聊天任务来了,它自动收紧阈值。
越跑越准,真正做到了自适应。
这10个概念单独拎出来,大部分确实算不上全新,但整套方案完成了算法、调度、硬件适配三位一体的端到端工程闭环。
而且DeepSpec全栈训练库一并开源,Eagle3、DFlash、DSpark三种草稿模型的训练代码全部放出,支持Qwen3和Gemma等外部模型——
你想给自己的模型训一个草稿器,直接拿过去改就行。
DSpark配套的DeepSpec库目前在GitHub已经拿下1.4k Star,各路开发者都开始实操内卷。
海外大佬看完论文火速掏出两块RTX PRO 6000在家折腾DSpark。
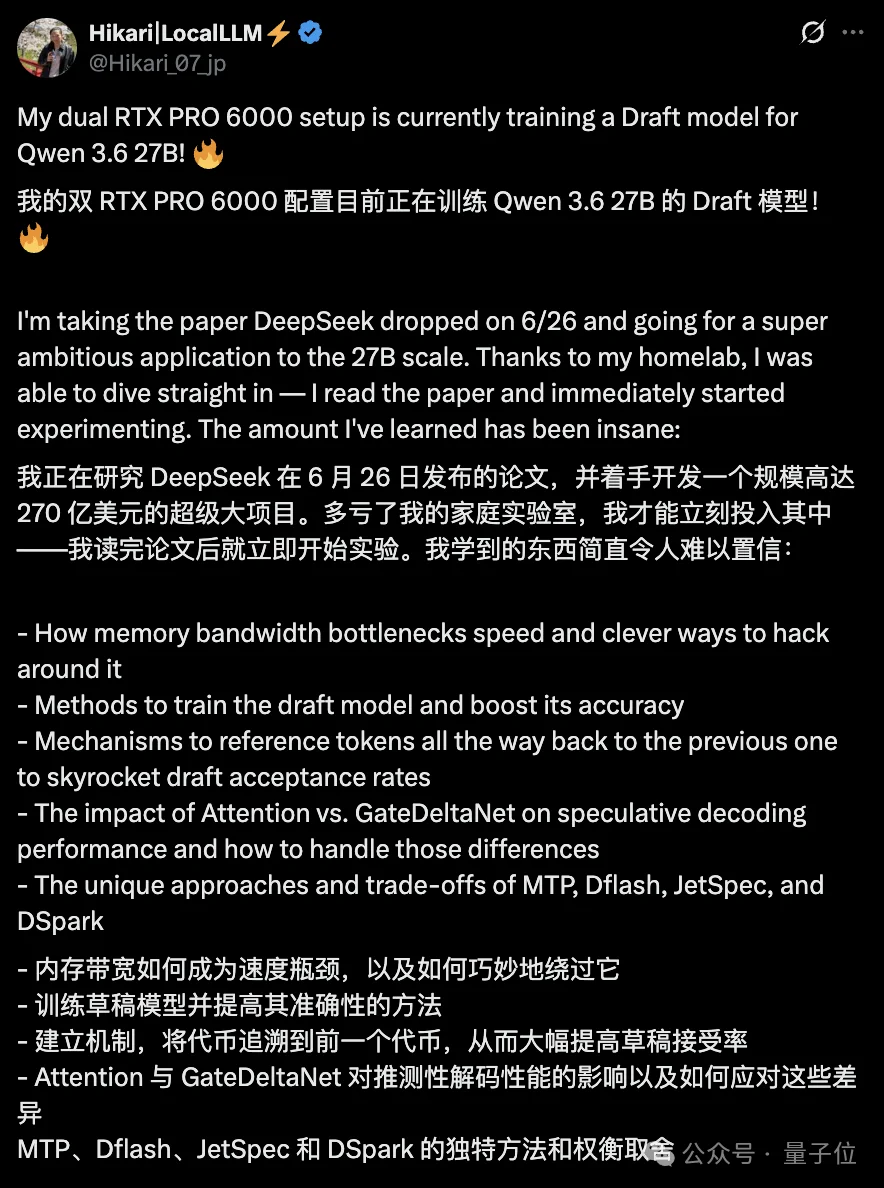
两块显卡火力拉满,看得出来很努力了(doge)。

论文地址:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
参考链接:
[1]https://x.com/dzhulgakov/status/2070922887595499930?s=20
[2]https://x.com/Hikari_07_jp/status/2070842526450479188?s=20
文章来自于微信公众号 “量子位”,作者 “量子位”



