# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
第一次看到杭州某家公司的宠物翻译器报道时,我的反应很直接:这不就是新一代智商税吗?

报道里的画面太熟悉了。一个小设备夹在猫狗项圈上,宠物叫一声,手机上立刻弹出一句人话:“我饿了”“我害怕”“快给我零食哄哄我”。再加上“基于大模型”“500万条声纹数据”“准确率94.6%”这些关键词,整件事看起来像是把养宠人的情感需求、AI热词和消费电子包装到了一起。
尤其是“翻译”这个词,很容易让人警觉。人类语言翻译的前提是两套语言系统之间存在稳定的词汇、语法和语义对应。猫叫一声,真的能对应成“走开点别碰我”吗?狗叫两下,真的等于“我只想安静地待着”吗?如果这也算翻译,那是不是太便宜了。
但我后来去翻了几篇相关研究,发现事情也不能简单一句“纯扯淡”打死。更准确的说法可能是:宠物叫声里确实有可分析的信号,机器学习也确实可能做出一定程度的情境分类;但这离“读懂宠物心声”还有很长一段距离,商用产品宣传里的高准确率尤其需要打一个很大的问号。
先说它“有东西”的部分。
动物叫声并不是毫无信息的背景音。以猫为例,Schötz、van de Weijer 和 Eklund 在 2024 年发表在 Applied Animal Behaviour Science 的研究中,分析了 50 只成年家猫在家庭环境中发出的 969 段喵叫。这些叫声来自拥抱、门口、食物、打招呼、被抱起、玩耍、猫包等不同场景。
研究者发现,不同场景下猫叫的韵律确实会变化。比如时长、平均基频和语调轮廓会受到情境影响;猫在猫包里的叫声更倾向于下降语调,而在食物、打招呼、亲昵等场景中的叫声更常出现上升或升降变化。作者的判断也很克制:这些韵律变化可能反映了猫所处情境中的情绪状态和唤醒水平。
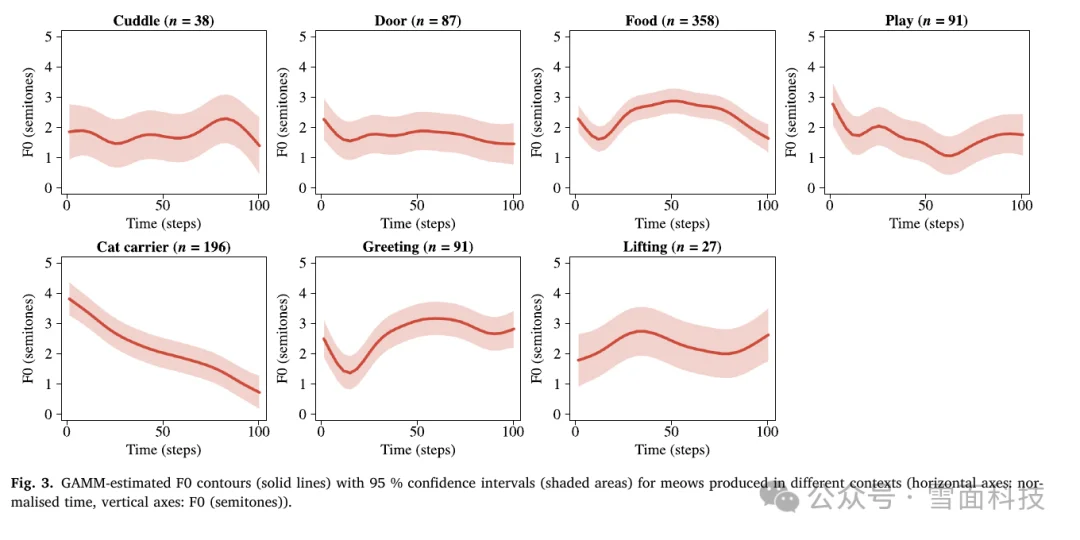
图源:Schötz, van de Weijer & Eklund, 2024, Fig. 3, CC BY 4.0。图中红线是不同场景下猫叫的基频轮廓,阴影是 95% 置信区间。最直观的是“cat carrier”这一组:猫在猫包里的叫声整体呈明显下降趋势。
论文要点节选(译意):作者认为,家猫喵叫存在与场景相关的韵律变化;这种变化主要体现在语调轮廓,也部分体现在时长和平均基频上。但他们同时提醒,韵律本身不足以解释猫叫的全部差异,后续仍需要结合声音质量、共振特征和视觉行为信号。
这说明什么?至少说明猫叫不是完全随机的“喵喵喵”。它里面有声学特征,有统计规律,也有可能被模型捕捉。
狗叫方面,类似结论更早就出现过。经典研究发现,狗叫的音高、音色、叫声间隔等参数,会影响人类如何判断狗的情绪。近年的机器学习研究也尝试把犬吠映射到情境,例如陌生人靠近、游戏、焦虑、攻击性叫声等。2024 年一篇关于犬吠分类的研究使用 Wav2Vec2 这类语音表示模型,在若干主要情境分类任务上达到约 60% 出头的准确率,显著高于多数类基线。
所以,如果一家公司说“我们能根据猫狗叫声和传感器数据,判断它可能处在什么状态”,这在科学上不是完全没根的。
真正的问题在于:从“状态分类”跳到“宠语翻译”,这一步太大了。
这类产品最容易混淆三个概念:声音识别、情境分类和意图翻译。
声音识别是:这是不是猫叫?是不是狗叫?是不是环境噪音?
情境分类是:这段叫声更像食物场景、隔离场景、玩耍场景,还是压力场景?
意图翻译则是:宠物真的想表达“我饿了”“我害怕”“别靠近”“想你了”。
前两个是可以用数据和模型去做的。第三个就复杂得多。因为“意图”不是宠物直接告诉你的,而是人类根据场景、行为和经验贴上的标签。
比如一只猫在饭点、饭碗旁、主人拿着罐头时发出叫声,人类标注员很容易把它标为“我饿了”。模型学到这个标签后,也许确实能在类似场景中识别出“食物相关叫声”。但这并不等于猫的叫声里有一个稳定语义单位,意思就是“我饿了”。它可能只是兴奋、期待、催促,也可能是“你怎么还没打开那个东西”。
换句话说,模型识别到的往往是“在某类人类可解释场景下出现的声音模式”,而不是宠物内心独白。
这也是我对“实时双向翻译”最怀疑的地方。把宠物叫声归到二十多个情绪/意图标签,已经不容易;再说人类语言能被设备反向翻译成“宠物语言”,让宠物理解,这就更像营销叙事了。猫狗当然可以学习声音、语调、关键词和主人的行为关联,但那不是语言翻译意义上的双向通话。
真正让我从“纯扯淡”变成“有点东西但仍然怀疑”的,是另一篇猫叫研究。
Prato-Previde 等人在 2020 年发表的 What's in a Meow? 做了一个很有意思的实验:让 225 名成年人听猫叫,然后判断这些猫叫来自三个场景中的哪一个:等待食物、隔离、梳毛。
结果并不乐观。即使只看最具代表性的猫叫,参与者的正确率也不高:等待食物是 40.44%,隔离是 26.67%,梳毛是 32.89%。研究者还指出,整体上人类对单段猫叫的具体场景辨别能力有限,猫主人和女性参与者表现会好一些,但这并没有把问题变得简单。
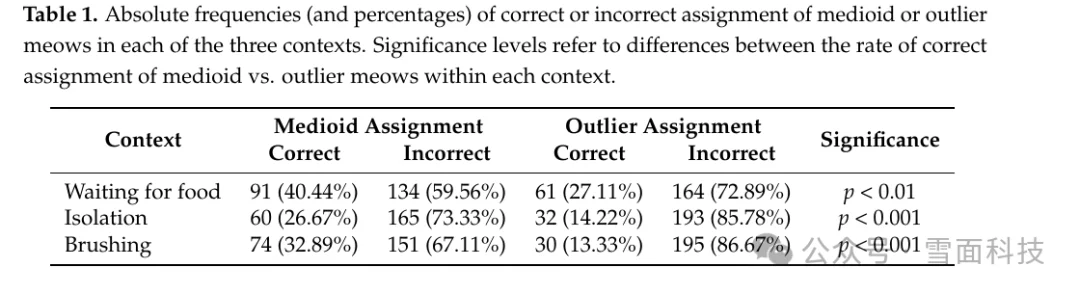
图源:Prato-Previde et al., 2020, Table 1, CC BY 4.0。这张表很适合给“94.6%准确率”降温:在这个实验里,即使挑出最有代表性的猫叫,人类判断具体场景也只有 26.67% 到 40.44%。
这篇研究特别重要,因为它提醒我们:猫叫确实有声学特征,甚至以前也有研究显示可以用声学参数做自动分类;但对具体情境和情绪的解释仍然很难。声音里面有信息,不等于信息足够明确;模型能找出统计相关,不等于它找到了宠物的真实意图。
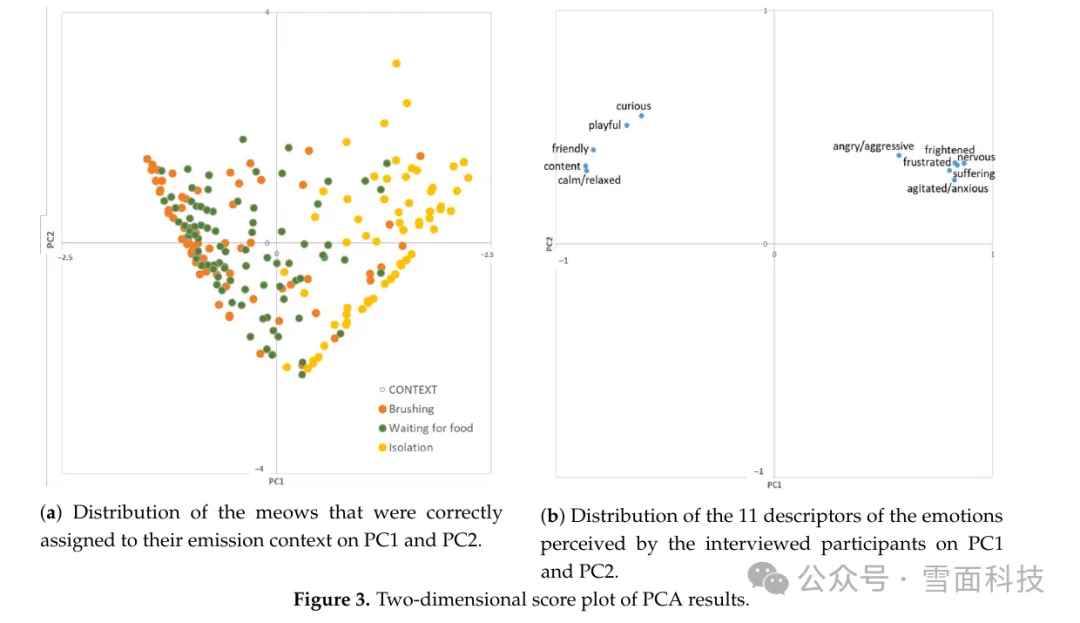
图源:Prato-Previde et al., 2020, Fig. 3, CC BY 4.0。右图把人类感知到的情绪描述词分成了较正向的一侧和较负向的一侧;左图则显示不同场景的猫叫在这种感知空间里有趋势,但并不是清清楚楚分成三堆。这正好说明:人类能感到“这像更紧张/更放松”,却不一定能稳定判断“这到底是哪一个具体场景”。
论文要点节选(译意):作者的结论不是“人完全听不懂猫”,而是成人只能有限地区分单段猫叫的发生场景;猫主人、女性参与者和对猫更有共情的人表现会更好一些,但总体能力仍然有限。
Schötz 等人的 2024 年研究也有类似克制。他们发现猫叫的语调、时长、平均基频会随场景变化,但同时明确提到,仅靠韵律无法解释猫叫的全部变化。不同个体、年龄、性别、情绪唤醒、环境噪声、麦克风距离、声音质量、身体动作,都可能影响结果。研究还建议未来要加入更高质量的音视频、声音质量、共振特征、视觉和触觉行为信号。
这跟消费级产品的宣传形成了强烈反差。学术论文里是“可能”“需要进一步研究”“仅靠韵律不够”;商业报道里则变成了“准确率94.6%”“全球首款AI宠语翻译器”“真正读懂毛孩子”。
中间差的不是一点点。
我并不是说 94.6% 一定是假的,但这个数字如果没有公开测试方法,几乎没有讨论价值。
它测的是猫狗声和环境声区分吗?如果是,那高准确率并不奇怪。
它测的是“食物、玩耍、害怕、压力”等少数大类情境吗?那还要看类别是否均衡,测试环境是否真实,宠物个体是否和训练集隔离。
它测的是二十多个“意图标签”吗?那就必须看每一类的 precision、recall、F1,而不是一个总准确率。
更关键的是,测试集怎么切分?
如果同一只猫的叫声既出现在训练集中,又出现在测试集中,模型可能学到的是这只猫的声纹、家里的混响、麦克风特征,而不是可泛化的“猫语”。如果同一个家庭、同一个饭点、同一种设备采集的样本被随机切开,准确率也很容易虚高。
一个真正有说服力的测试,应该至少做到:训练集和测试集里的宠物个体隔离;最好连家庭环境也隔离;在真实家庭噪声中测试;报告每个标签的混淆矩阵;允许模型输出“不确定”;并由独立第三方复测。
否则,“94.6%准确率”很可能只是一个在特定数据集、特定标签定义、特定切分方式下成立的漂亮数字。
这也是为什么我会拿学术研究里的 40%、60% 来做参照。不是说商业产品不能超过论文。它可能有更多数据、更好的模型、更强的硬件传感器,当然有机会做得更好。但当公开学术研究在更谨慎的任务设定下还只做到有限准确率时,一个刚成立几个月的消费产品突然宣布接近 95% 的“翻译准确率”,至少应该要求它拿出同等透明的证据。
如果把这类设备看成“宠物电话手表”,其中有些功能是实用的:定位、防走失、活动量记录、叫声异常提醒、长期行为变化监测。这些功能不需要它真的懂猫语,也能产生价值。
如果把它看成“宠物状态提示器”,我也愿意承认它有潜力。比如它提示“这段叫声更接近压力场景”“最近夜间叫声明显增加”“今天活动量下降”,这些都可能帮助主人更早注意到宠物状态变化。
但如果它被包装成“宠物翻译器”,尤其是把一句句拟人化台词塞进手机聊天框里,我的怀疑就会回来。
因为这种设计会制造一种错觉:主人以为自己听到了宠物的真实想法。问题是,错误的“翻译”有时比没有翻译更危险。猫明明可能因为疼痛或压力在叫,App 却翻译成“我想撒娇”;狗明明处在恐惧防御状态,App 却说“我想玩”。这不仅误导主人,也可能延误观察和就医。
宠物不会因为 App 上出现一句可爱的中文,就真的被理解了。
所以我现在的态度是:不再当成纯扯淡,但也绝不把它当成真正的翻译。
宠物叫声里确实有规律。AI 确实可以从声学特征、动作传感器、长期个体数据中做状态分类。随着数据积累,这类系统也许会越来越有用。
但“有规律”不等于“有语言”;“能分类”不等于“能翻译”;“实验准确率高”不等于“真实家庭里可信”;“宠物行为标签”更不等于“宠物心声”。
注:文中的“论文要点节选”均为译意概述,不是逐字翻译;图表来自OA论文,并在图注中标明原始来源和许可。
文章来自于"雪面科技",作者 "XueMian"。


