# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
老黄在北京喝豆汁「翻车」,全网笑疯了。但真正值得警惕的,是他背后那个正在长出来的「中国版CUDA生态」。从万卡集群到机器狗,从SGLang主线到AI Agent自动迁移,这家公司这次不只是秀芯片,而是在重写国产GPU的游戏规则!
这几天,老黄喝豆汁的表情包,已经在全网刷屏了。

他穿着黑色皮衣,端着炸酱面,站在方砖厂69号门口边拌边吃。
有人递过来一碗豆汁,他喝了一大口,眉头瞬间拧成一团,周围一片哄笑。
但他这次来北京,显然不只是来吃面的。
老黄自己说过一句话,「不要低估中国的实力和竞争力,那是愚蠢的。」
5月18日晚,炸酱面热搜还没凉,摩尔线程在北京开了年度产品发布会。
但所有这些硬件背后,有一条贯穿全场的主线——MUSA生态。
CUDA统治AI算力十五年,靠的不是芯片快,靠的是生态锁定。
几百万开发者的代码、习惯、工具链,甚至手指敲键盘的肌肉记忆,都长在CUDA上面。
换平台?重写代码、重学工具、重新踩坑。硬件采购只是一张订单,工程迁移是一场组织动员。
你能造出神兵利器,但很难改变几百万人的生活习惯——这才是卡脖子卡得最见血的地方。
所以国产GPU的竞争,到了今天,已经从「硬件替代」推进到「生态替代」。
硬件替代解决的是有没有卡,生态替代解决的是开发者愿不愿意来、模型能不能跑、行业敢不敢规模化采购。
如今,MUSA已经实现了芯片架构、指令集、编程模型、软件运行库、驱动框架和上层应用工具链的全面覆盖。

从云端万卡集群到个人算力本再到边缘SoC模组,跑的都是同一套MUSA。大模型训练、推理服务、智能体、机器人仿真,全部长在这同一个底座上。
这意味着他们卖的不是某一颗芯片、某一张卡,而是一整套国产全功能GPU的底层生态。
具体来说,MUSA生态的进展可以拆成四个台阶。
兼容,原生,开放,自进化。
每往上一层,MUSA的角色就发生一次变化。
前两层解决迁移和性能,第三层解决开发者入口,第四层开始改变生态建设的成本结构。
第一层是兼容:先把开发者的旧代码吃下来
国产GPU应用最大的障碍之一,是迁移成本。
开发者已经习惯CUDA、PyTorch、cuDNN、Triton、vLLM、SGLang这一整套工具链。如果换一张卡就要重写工程、重新调试、重新踩坑,再漂亮的硬件指标也很难变成采购决策。
MUSA SDK 5.1.0直接对标CUDA 12.8,驱动及运行时API兼容数干到761个。
核心数学库Blas、Sparse、Rand、FFT,100%功能兼容。
AI算子库muDNN覆盖55类核心AI算子,额外扩展230多个。
PyTorch全量3194个算子,100%兼容,不是「大部分能凑合跑」,是全量。
绝大多数CUDA程序不改一行代码,直接在摩尔线程的卡上跑通。开发者凭肌肉记忆写出来的代码,MUSA全吃下了。
迁移成本越低,试用意愿越强。原有代码越能复用,组织内部推进国产算力,出错的风险和投入的成本都会大大降低。
第二层是原生:光能跑还不够,关键路径必须跑得快
兼容解决的是「能不能迁」,原生性能解决的是「迁过来值不值」。如果关键路径上性能拉胯,客户最后还是会把你放在备用方案的位置。
MATE加速库直接对着大模型最吃算力的几个算子开刀。FlashAttention3、Sage Attention、DSA、GDN、DeepGEMM,全是硬骨头。
FA3在摩尔线程GPU上效率飙到95%,热点算子覆盖率突破90%,Attention类算子全场景覆盖。
大模型训推的瓶颈从来不在「所有功能都支持」,而在Attention、GEMM、MoE通信、KV Cache这几条高频路径上。这几条路卡住,整套系统就被拖住。FA3到95%,意味着MUSA在最要命的环节上跟CUDA的差距已经是个位数。
此外,MUSA还新增了Fortran编译器,VASP等科学计算软件可以直接迁移。

TileLang-MUSA已经合入开源主线,GEMM类算子实现95%以上的汇编级性能效率,Attention类算子达到90%以上。
Triton-MUSA升级支持到Triton 3.6最新版本。
这些工具看起来离普通读者很远,但它们决定了硬核开发者愿不愿意在这个平台上写底层算子。
客户不会为情怀长期付费,只会为效率、稳定性和确定性付费。MUSA如果能在关键路径上持续接近原生效率,它的身份就会从「兼容层」变成「高性能开发平台」。
第三层是开放:进主线,才算真正上桌
整场发布会里,这一层的战略分量可能最重。
全球顶级推理引擎SGLang,已经将MUSA合入官方主线,并列入2026 Q2官方硬件支持矩阵,和GB200/GB300、AMD、TPU并列。
截至5月12日,摩尔线程在SGLang上提交47个PR,合并41个。
在vLLM那边,MUSA同样拿到官方后端身份。TileLang-MUSA也已经合入开源主线。

开发者在使用时,直接调用的就是框架。
框架支持谁,代码就能跑在谁的卡上。框架不支持,芯片再猛也是孤岛。
现在代码进入SGLang和vLLM主线,开发者在官方文档里就能看到MUSA后端。后续新模型、新工具、新推理策略的适配成本,会明显下降。
模型适配层也是同一个逻辑。
摩尔线程MTT S5000目前已完成DeepSeek V4、GLM-5.1、Qwen3.5、MiniMax M2.7、Kimi K2.6等大语言模型的深度适配。视觉理解和多模态模型也覆盖了Qwen3-VL-235B/8B和Wan 2.2。
重点在于Day-0。模型发布当天,MUSA算力就已经就位。
在大模型一个月一迭代的今天,客户关心的不只是某个历史模型能不能跑,而是下一个热门模型出来时,自己的算力底座能不能及时变成可用服务。
Day-0适配能力,本质上是在争夺模型时代的时间窗口。
更深一层看,中国最头部的大模型和国产算力底座同步就位,意味着从算法到硬件的完整链路正在变厚。
这条内循环一旦跑起来,每一次模型迭代都会给生态添一层土,而不是把已有系统再冲散一次。
第四层是自进化:让Agent替生态搬砖
前三层讲的都是「MUSA能做什么」。这一层讲的是「MUSA怎么越滚越快」。
如果生态建设一直靠工程师手工适配,摩尔线程永远会被全球开源社区的版本节奏推着跑。CUDA的护城河本质上是十五年的时间积累,手工追赶注定辛苦,而且很难越追越轻松。
要击穿这道时间壁垒,得改变积累速度本身。
MUSACODE是摩尔线程给出来的答案。自研AI编程工具,自然语言直接生成MUSA代码,覆盖Python、C++、Rust、Go,代码完全本地运行。
30天,自动生成并测试PP库12015个算子。基于TileLang自动调优Group GEMM算子实现60%性能提升。

Automusify Skill则是一个零人工干预的AI Agent,它的任务就是全自动代码搬家。Top 100人工智能加速库、Top 100科学计算加速库,100%自动平移到MUSA上。
过去建生态靠刀耕火种,工程师熬夜一行行手写适配。现在直接跨入工业革命,AI Agent、编译器、自动测试、在线仓库串成流水线,别人每多发布一个框架、一个库、一个模型,MUSA就能更快完成迁移和优化。
这才是真正改变游戏规则的地方。生态建设不再是人海战术,而是一台自带加速度的飞轮。
MUSA服务AI,AI反向加速MUSA。飞轮一旦转起来,十几年的时间差可以被压到一个完全不同的量级。

发布会后半段,MUSA开始见真章。
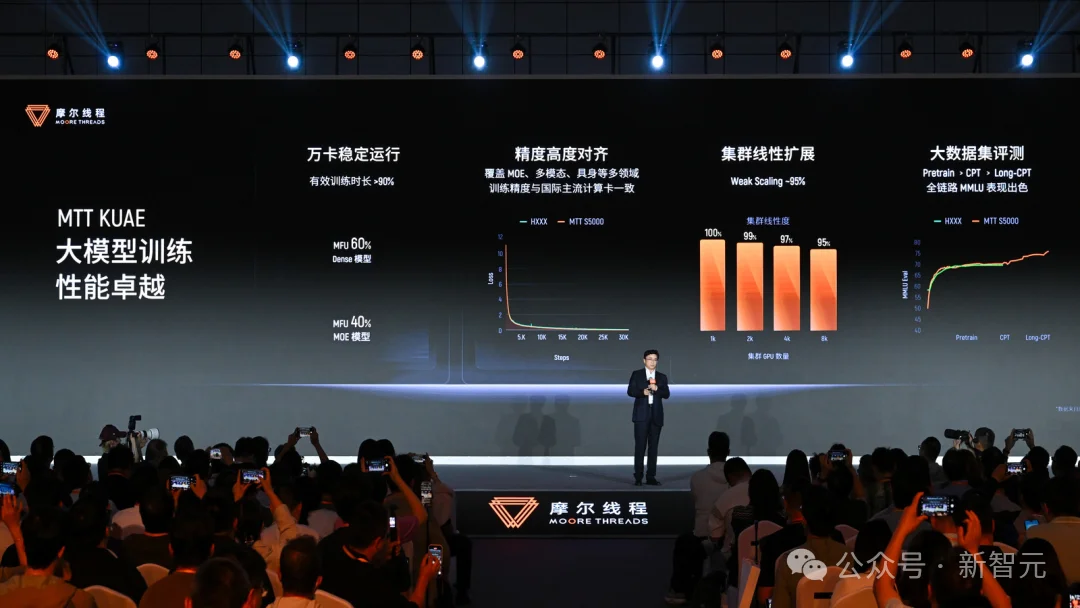
云端,夸娥万卡集群商业化落地,Dense模型MFU干到60%,MoE达到40%,有效训练时长超过90%。

根据官方介绍,S5000集群训出来的模型精度能跟国际先进水平对齐,大模型公司不用再担心国产集群训练质量。
一段两分钟的AI短片「地球最后一朵算力花朵」在大屏幕上播出来,用Wan模型跑在夸娥上,一个人短时间搞定,台上说以前这是好莱坞导演花大价钱才能拍的东西。
端侧,AICUBE把智能体、AI PC和AI NAS塞进一个巴掌大的铝合金立方体,6月18日京东预售。

AIBOOK预装OpenClaw,可以同时跑12个智能体。
现场,研究员直接拉起5个数字员工,几分钟就交出了一整套新品企划。
用摩尔线程创始人、董事长兼CEO张建中的话说就是,「任何一个年轻人创业,有一台AIBOOK就可以开一人公司。」
压轴的是一只叫「小飞」的机器狗,只见它一个干拔,做了个侧空翻,然后稳稳落地,纹丝不动。
别小看这个跟斗——它背后藏着MUSA在具身智能场景里真正的杀手锏。
具身智能跟大模型训推不一样。
它需要物理仿真、图形渲染、AI推理、端侧部署同时跑。传统方案把这些任务扔给不同硬件,数据反复搬运,延迟拉满。
摩尔线程的全功能GPU在MT Lambda仿真平台里,把物理引擎AlphaCore、光子引擎MT Photon、3DGS渲染和Torch-MUSA放在同一套链路里。
「物理+渲染+AI」三大引擎同一颗芯片,数据零拷贝。

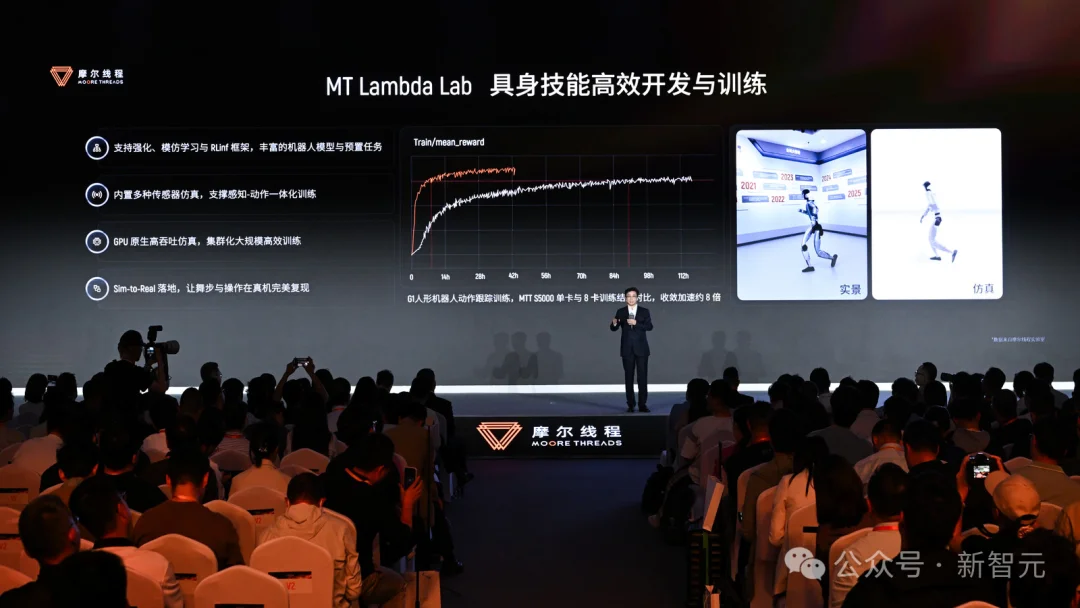
今年3月摩尔线程开源了MuJoCo Warp MUSA,首个国产GPU加速的物理仿真后端。
和智源研究院合作的RoboBrain 2.5端到端训练,结果跟H100集群误差小于0.62%。机器狗训练任务中,MT Lambda比CPU方案快40倍。
小飞身上跑的运动策略,在Lambda平台训好后,零调参直接下发到「长江」SoC执行。
所有这些,不管是拍短片、开一人公司,还是训模型或机器狗,虽然跑在不同规模的硬件上,但用的是同一条技术脊柱。

一套从底到顶跑通了的生态,和一堆零散的兼容能力,是完全不同的东西。
前者会产生网络效应。开发者越多,生态越厚;用得越久,迁回去的成本也越高。口子一旦撕开,就合不上了。

从100%兼容到SGLang官方合入,从Day-0模型适配到Agent自动搬家,从全功能GPU三引擎合一到机器狗零调参落地,摩尔线程这场发布会展示的是从软件栈、开发者生态到物理世界应用的全链路贯通。
更关键的是,这套生态跑通全链路,依托的还是当前第四代「平湖」架构。
去年12月,摩尔线程已经发布第五代「花港」架构,算力密度再升50%,能效提升10倍,支持FP4到FP64全精度,可撑起十万卡互联。基于花港的AI芯片「华山」,在有序推进中。
换句话说,MUSA生态打通全链路时,还没用上摩尔线程最强的那张牌。
方砖厂69号店门口,现在挂着「皮衣战神同款套餐」的招牌。
但CUDA同款生态的招牌,已经不再是唯一选择。
文章来自于"新智元",作者 "新智元"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
