# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
【导读】Sam Altman 今天在 X 上扔出一个数字:ChatGPT Images 2.0 在印度已经生成超过 10 亿张图。距离产品发布只有 27 天。TechCrunch 和第三方数据验证了印度确实是最大市场——但全球增长远没有那么均匀,这更像一场区域性起飞。
5 月 18 日,OpenAI CEO Sam Altman 在 X 上发帖:
"ChatGPT Images 2.0 💚 India. Already more than 1 billion images created there; awesome to see."
「ChatGPT Images 2.0 爱印度。那里已经生成超过 10 亿张图,看到这个太棒了。」
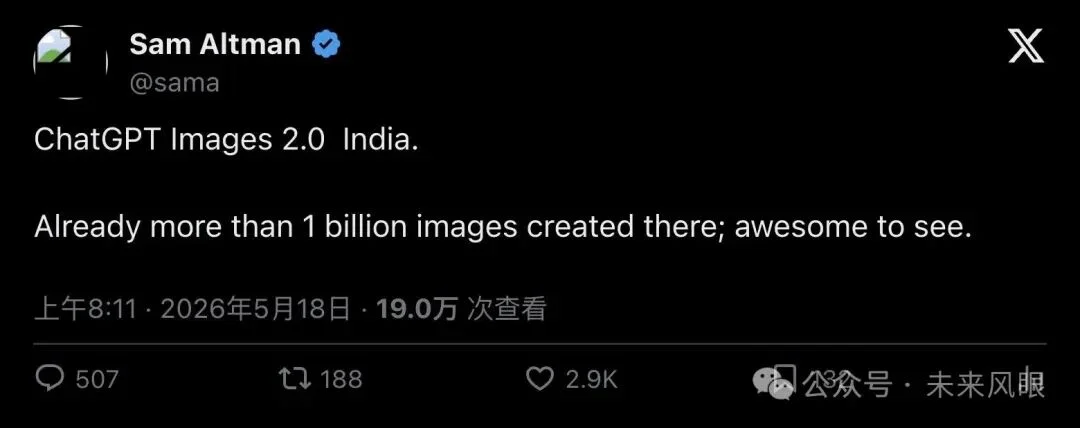
▲ Sam Altman 在 X 上公布印度 10 亿图数据
10 亿张。27 天。单一国家。
需要注意,这个数字目前唯一来源就是 Altman 本人的社交账号,没有出现在任何官方报告或产品博客里。但即便如此,这个量级也足够让人停下来想:到底发生了什么?
早在 4 月底,TechCrunch 就已经捕捉到了这个信号。
"India has emerged as the largest user base for ChatGPT Images 2.0 since its launch last week, OpenAI said on Thursday."
「OpenAI 表示,印度已成为 ChatGPT Images 2.0 上线以来最大的用户群。」
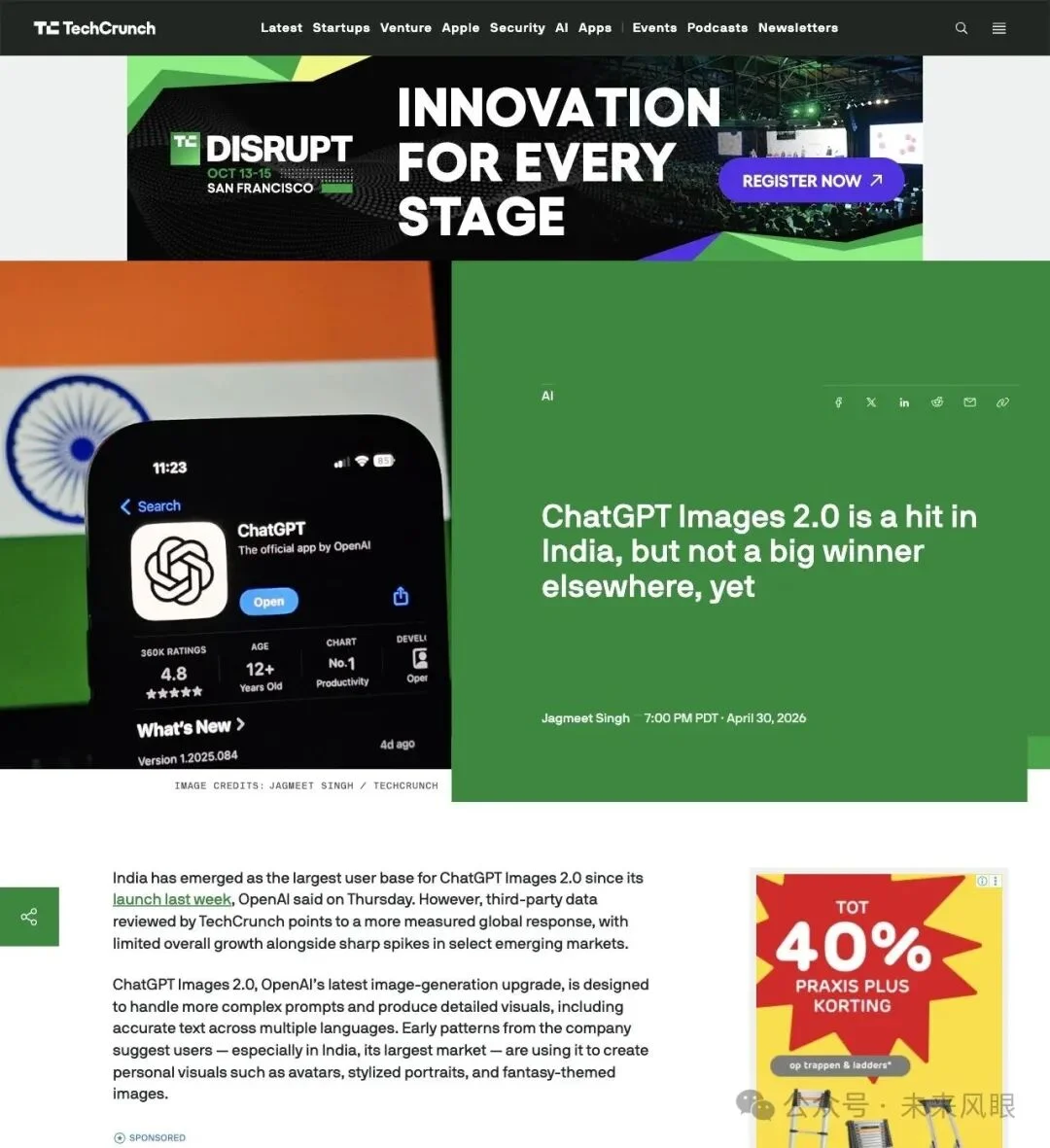
▲ TechCrunch 4 月 30 日报道:印度是 Images 2.0 最大市场,但全球增幅有限
Sensor Tower 的数据显示,Images 2.0 上线首周,ChatGPT 在印度的下载量约500 万次,美国约200 万次——印度是美国的 2.5 倍。
但全球数据远没有那么夸张。Sensor Tower 估算全球下载周环比只增长了11%,DAU 和使用时长几乎没变,只涨了约1%。Similarweb 的数据也类似:全球 web 端流量周环比只增加了1.6%,印度的 DAU 涨幅稍高,约3.4%。
换句话说,全球整体反应相当平静。增长高度集中在印度、巴基斯坦、越南、印尼等新兴市场。
那为什么偏偏是印度?
TechCrunch 提到了关键线索:印度用户拿 Images 2.0 做的事情方向明确——个人写真、社交头像、婚礼和节庆海报、WhatsApp 分享图、小商家产品图。全是高频、刚需、视觉表达密集的场景。而印度恰好是全球最大的 WhatsApp 市场,移动互联网用户超过 7 亿。
Altman 帖子下面,用户 @jahanzaibai 的评论指向了同一个方向:印度的 WhatsApp 生态和电商基础设施会让 AI 生成的图片直接流入真实商业链路——从个人收藏变成商业素材。
4 月 21 日,OpenAI 发布 ChatGPT Images 2.0 时,同步公开了系统卡(System Card)。
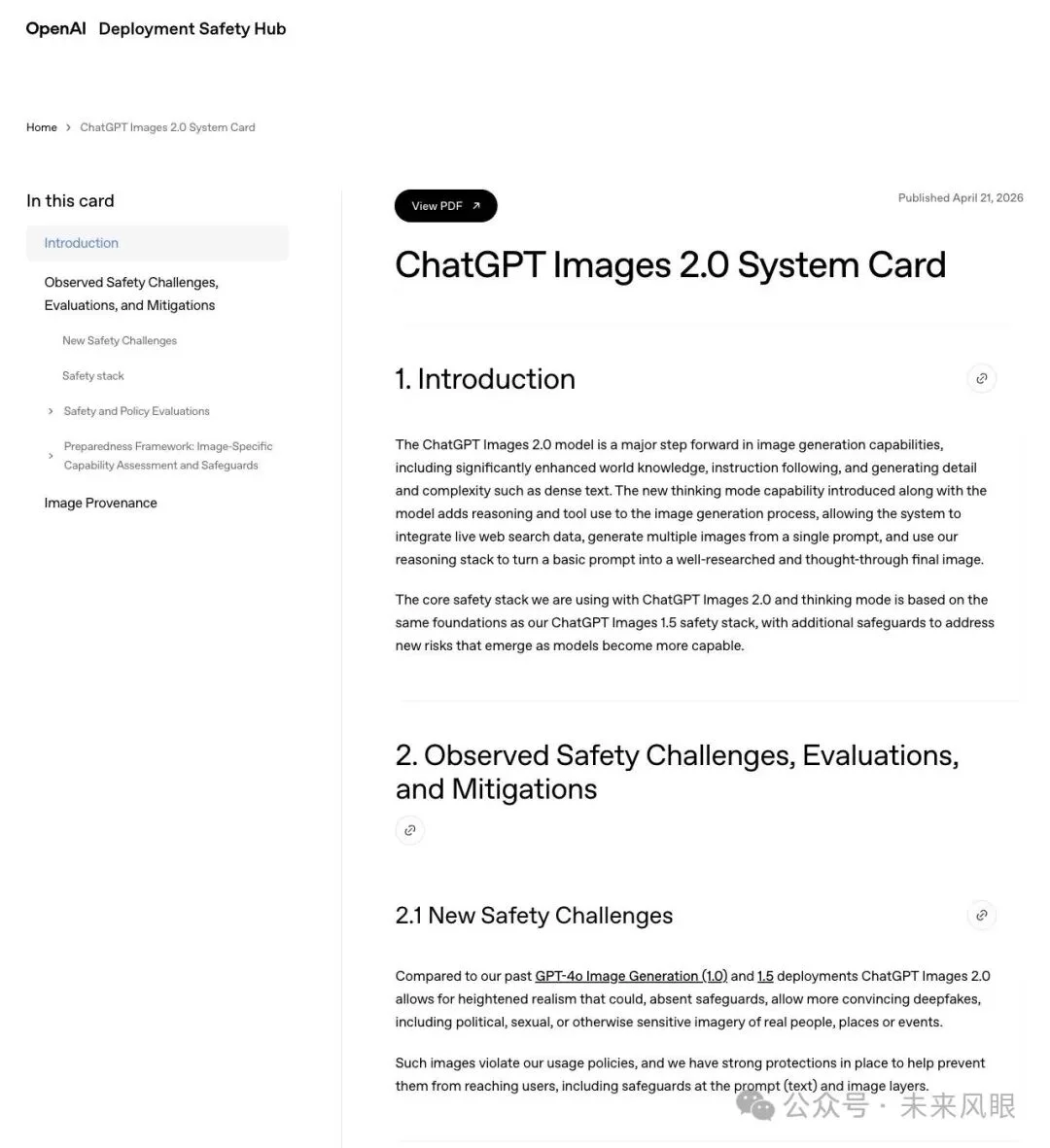
▲ OpenAI 系统卡详细说明了 Images 2.0 的能力升级与安全风险
系统卡给出的核心升级方向:
"The ChatGPT Images 2.0 model is a major step forward in image generation capabilities, including significantly enhanced world knowledge, instruction following, and generating detail and complexity such as dense text."
「Images 2.0 在图像生成能力上大幅提升,尤其是世界知识、指令遵循、以及密集文本等复杂细节的生成。」
密集文本生成——这个能力在印度市场尤其关键。用户可以直接用它做带文字的海报、信息图表、产品标注图,而且支持多语言。对印度这样一个 Hindi、Bengali、Tamil、英语混排的环境来说,这直接解决了过去请设计师排版的痛点。
另一个重要升级:thinking mode。模型在生图前先推理,可以调用 web search、生成多个变体、把一个粗糙 prompt 补充成完整方案。门槛大幅降低——用户不需要会写专业 prompt,给个大概方向就能出图。
OpenAI Developer Community 的公告补充了产品定位:
"This release is built for production workflows, where images need to be accurate, readable, on-brand, localized, and formatted for destination surface."
「这个版本面向生产工作流——图像需要准确、可读、品牌一致、本地化,并适配最终展示平台。」
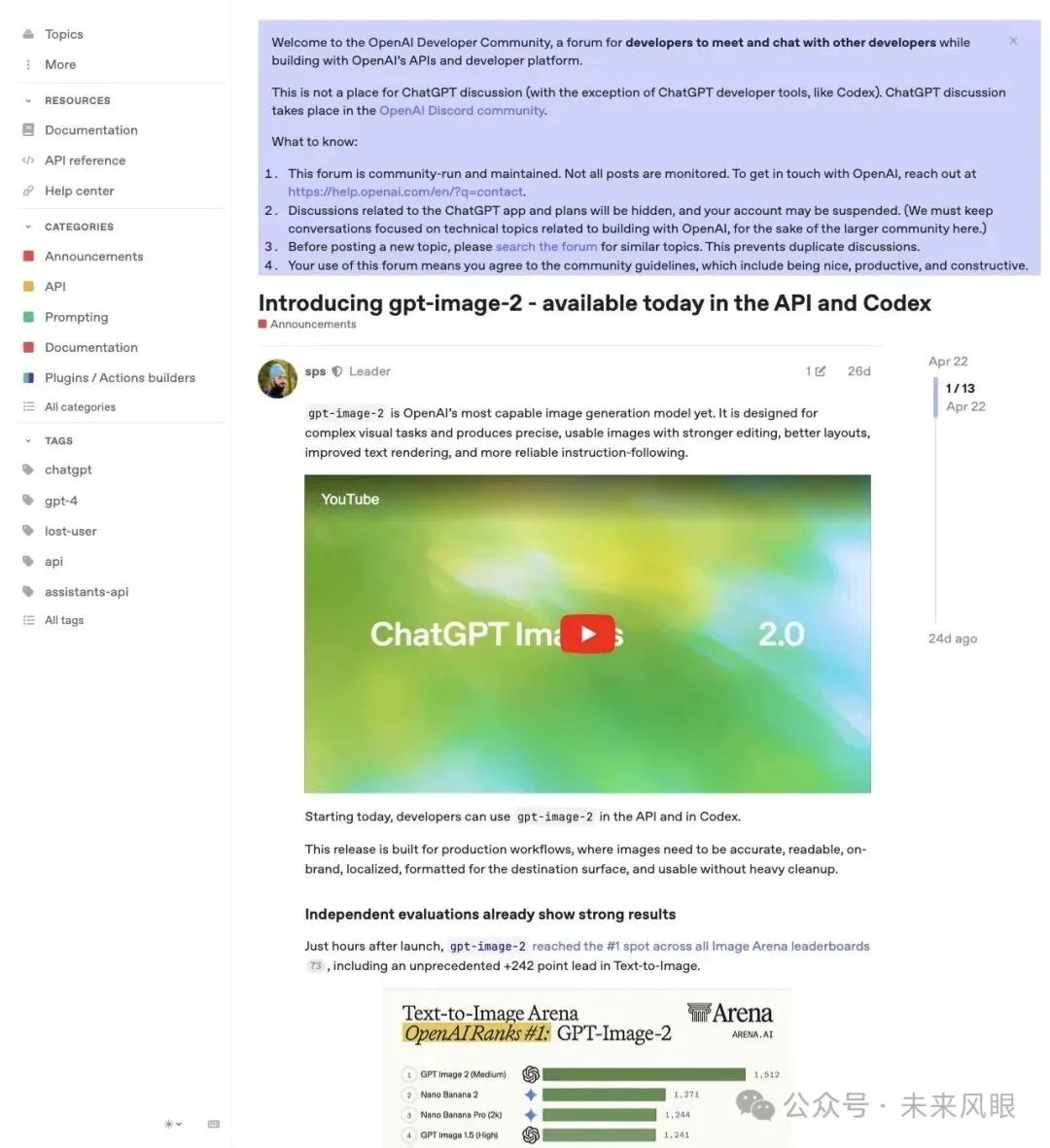
▲ gpt-image-2 在 Image Arena 排行榜上线即登顶
gpt-image-2 上线数小时后在 Image Arena 排行榜全线登顶。API 和 Codex 接口同步开放,开发者可以直接把它嵌入应用和工作流。
▲ OpenAI 官方发布页:"A new era of image generation"
10 亿张图的另一面,是同比例放大的风险。
OpenAI 自己在系统卡里就提到了这一点:Images 2.0 的高度真实感会让 deepfake 和敏感人物/事件的虚假图像更加逼真、更有欺骗性。目前的应对措施包括 prompt 层和图像层的安全过滤、C2PA 元数据标记和水印——但 OpenAI 也承认,现阶段没有单一的 provenance 方案能彻底解决这个问题。
社交媒体上的质疑也在同步升温。
用户 @OxygenGain 直接问:"生成这些大多没用的图消耗了多少电力?"
@full_kelly_ 的批评更尖锐:十亿张图,意味着大量 slop(低质量垃圾内容)被批量制造出来。
@ValeriusLabs 关注的是推理成本——十亿级的图像生成,背后的 inference 开销必然是天文数字。
还有一个矛盾但真实的声音来自 @Balu0X:Images 2.0 确实是目前最强的图像生成模型,但限制太多。能力认可和使用不满并存——这可能是 OpenAI 下一阶段不得不面对的产品博弈。
10 亿这个数字背后,浮现出一个更大的趋势:AI 图像生成正在从创作者的专业工具,变成普通用户的日常视觉表达方式。
想发一张节日祝福?生成。想给自己的小店做个海报?生成。想要一张好看的社交头像?生成。
就像输入法一样——想表达什么,直接出图。
印度的爆发有它的必然性。14 亿人口、极高的移动互联网渗透率、WhatsApp 主导的社交生态、旺盛的视觉表达需求,再加上一个终于能用母语直接出带文字图片的 AI 工具——所有条件在同一个市场叠加到了一起。
但边界也摆在眼前。10 亿张图来自 Altman 个人社交平台口径,没有公开统计方法;全球增长远不均匀,印度的故事未必能平移到其他市场;deepfake、内容垃圾和能源消耗的治理压力,会随着生成量级一起膨胀。
当 AI 生图变成像打字一样自然的事,准备好了吗?
文章来自于"未来风眼",作者 "未来风眼"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
