


只需2分钟,单视图3D生成又快又好!北大等提出全新Repaint123方法
只需2分钟,单视图3D生成又快又好!北大等提出全新Repaint123方法将2D扩散模型的强大图像生成能力与再绘策略的纹理对齐能力结合起来,Repaint123能够在2分钟内从零开始生成具有多视角一致性和精细纹理的高质量3D内容。
来自主题:
AI资讯
10765 点击 2024-01-08 13:53
 搜索
搜索
将2D扩散模型的强大图像生成能力与再绘策略的纹理对齐能力结合起来,Repaint123能够在2分钟内从零开始生成具有多视角一致性和精细纹理的高质量3D内容。

据知名苹果爆料人马克·古尔曼周日(1月7日)称,科技巨头苹果公司正准备在今年6月的全球开发者大会(WWDC)上推出一系列基于生成式人工智能(AI)的工具,这将是朝着未来迈出的一大步。

机器人的ChatGPT时刻,真来了!初创公司Figure自家机器人看了10小时视频,学会了煮咖啡。另一边,东京大学GPT-4加持的Alter3机器人,能够模仿人类做出任何动作。而人类只需发出自然语言指令即可,完全不需要编程!

大模型推理再次跃升一个新台阶!最近,全新开源的国产SwiftInfer方案,不仅能让LLM处理无限流式输入,而且还将推理性能提升了46%。

版权法是一把悬在 AI 公司头上的利剑。当《纽约时报》正式宣布起诉 OpenAI 和微软侵权时,这把利剑的锋芒再度展露,似乎在预示着 2024 年又将是树立里程碑的一年。

近日,斯坦福华人团队的Mobile ALOHA“全能家务机器人”在网上爆火,它展示了做饭、铺床、浇花等多种家务技能,可谓是全复合“保姆人才”。

我对AI的信心从来没像这一刻这么强。这不是激进,能和这篇文章要一起看的是《为什么说AI现在还不行》,看着有点矛盾,但其实是一个事情的正反两面,统一于尺度判断。
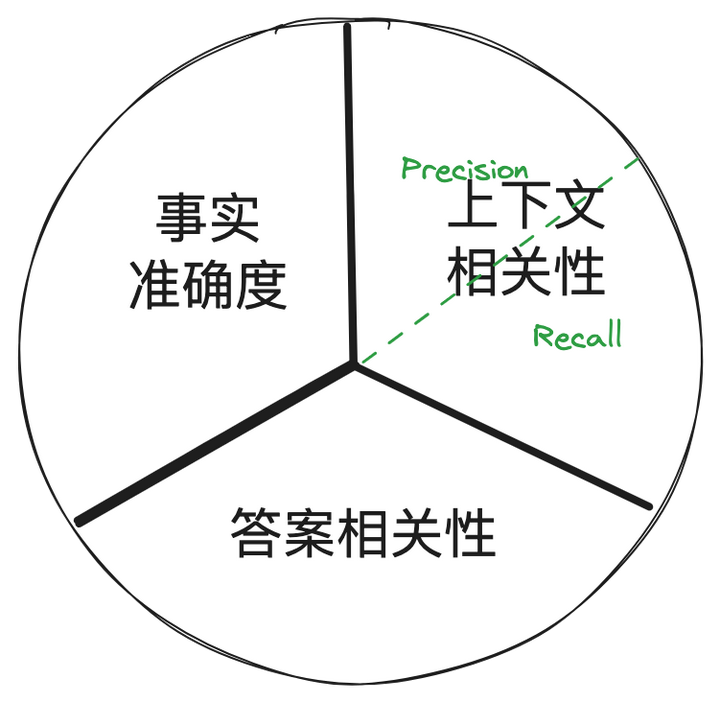
做所有的工作之前,想好如何评估结果、制定好北极星指标至关重要!!! Ragas把 RAG 系统的评估指标拆分为三个维度如下,这可不是 Benz 的标...

伴随着最近chatGTP爆火网络,AI已经逐步渗透教育、生活、工作、就业、金融等各大领域。但与此同时,人们对人工智能飞速发展带来的隐患也愈发担忧。究竟AI是科技进步的象征还是人类的威胁?文章来自翻译,希望能对你有所启示。

作为一个「AI 助手」,ChatGPT 在手机上还是不够方便,不信你比较下手机自带的语音助手,通常是一键、一划、一呼就能呼出进行对话,肯定要比打开 ChatGPT App、点击语音或者输入框进行输入来得方便。

CSRankings 2024结果出炉!全世界计算机科学机构的排名进行了大更新。在AI板块,清华、北大、上交分列TOP 3,CMU和浙大并列第4。AI TOP 10中的中国高校,还包括人大、南京大学、复旦大学、哈工大等。

神经网络由于自身的特点而容易受到对抗性攻击,然而,谷歌DeepMind的最新研究表明,我们人类的判断也会受到这种对抗性扰动的影响

AI算命将可以预测人类的意外死亡?丹麦科学家用全国600万人的公开数据训练了一个基于Transformer的模型,成功预测了意外死亡和性格特点。

2023年,被全球咨询巨头麦肯锡称为“生成式AI的爆发之年”。这一年里,AIGC技术快速发展,越来越多的AI工具如雨后春笋般涌现,使得AI在各行各业的深度应用成为可能。
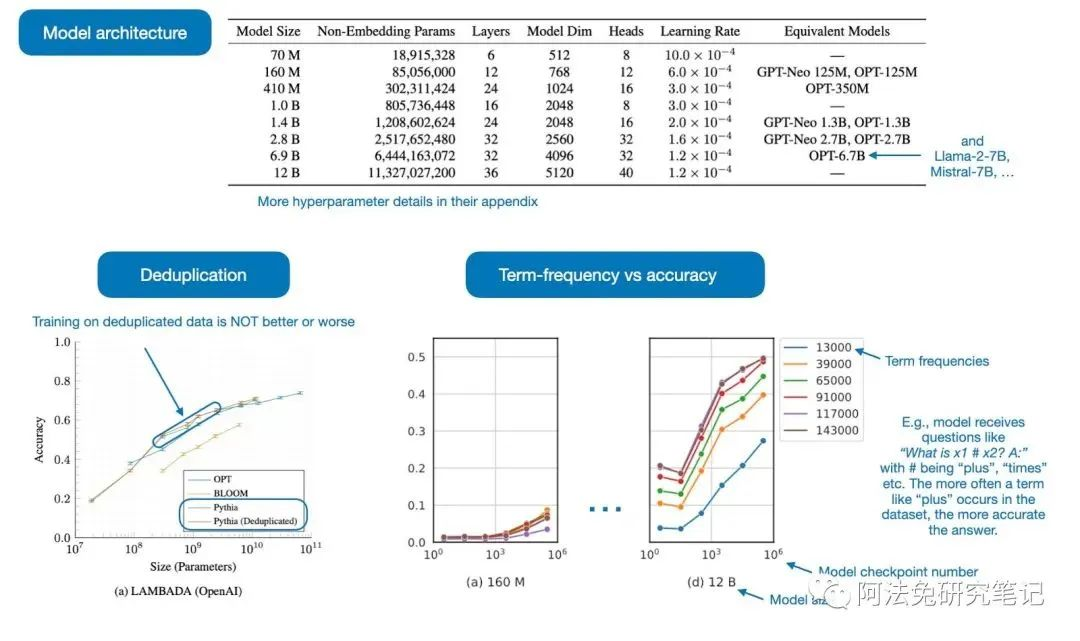
2023 年,是机器学习和人工智能发展最为迅速的一年,这里分享 10 篇最值得关注的论文。

大模型没有壁垒,结合多年深耕的场景和数据处理技术才是王道。

前不久,OpenAI“煞有其事”地像谷歌、苹果那样办了第一场较为正式的“开发者大会”。从大会透露的信息来看,大模型的下一站很明确——想搞钱,得教人“玩”大模型了,拉更多的人来做大大模型市场的蛋糕。

2024年了,被寄予厚望的AI Agent,到底是谁在用啊?!
一级市场,要被AI彻底颠覆了?找项目不用靠投资经理,AI可以代替了。 EQT靠AI挖水下项目,成绩不俗,已经完成了15笔交易,其中2笔交易估值超10亿美元,妥妥独角兽级别,还有1笔已经被收购。

在过去短短两年内,随着诸如 LAION-5B 等大规模图文数据集的开放,Stable Diffusion、DALL-E 2、ControlNet、Composer ,效果惊人的图片生成方法层出不穷。图片生成领域可谓狂飙突进。

同济大学王昊奋研究员团队联合复旦大学熊赟教授团队发布检索增强生成(RAG)综述,从核心范式,关键技术到未来发展趋势对 RAG 进行了全面梳理。这份工作为研究人员绘制了一幅清晰的 RAG 技术发展蓝图,指出了未来的研究探索方向。
语言模型究竟是如何感知时间的?如何利用语言模型对时间的感知来更好地控制输出甚至了解我们的大脑?最近,来自华盛顿大学和艾伦人工智能研究所的一项研究提供了一些见解。

谷歌新设计的一种图像生成模型已经能做到这一点了!通过引入指令微调技术,多模态大模型可以根据文本指令描述的目标和多张参考图像准确生成新图像,效果堪比 PS 大神抓着你的手助你 P 图。

琳琅满目的乐高积木,通过一块又一块的叠加,可以创造出各种栩栩如生的人物、景观等,不同的乐高作品相互组合,又能为爱好者带来新的创意。

爆火的斯坦福全能家务机器人Mobile ALOHA,大!翻!!车!!!你以为它擦个红酒轻而易举,但实际上却是这样的:

AIGC在商业界中,最大的一笔回报是多少?答案可能是:一张图片,500元。

一句话定位视频片段

解决扩散模型「不识字」的问题,Textdiffuser采用两阶段(布局+图像)生成框架,显著提升了相关性能的指标!

最近,来自NUS、斯坦福、谷歌DeepMind等机构的研究人员,尝试开发了一个评估人类和AI的创造力的框架。而当人类用尽所有手段来逼迫AI把创造力发挥到极限,发现GPT-4几乎对于所有事物认知的极限都是无尽的宇宙空间。

在 AI 领域,近年来各个子领域都逐渐向 transformer 架构靠拢,只有文生图和文生视频一直以 diffusion + u-net 结构作为主流方向。diffusion 有更公开可用的开源模型,消耗的计算资源也更少。

