

推理延展到真实物理世界,英伟达Cosmos-Reason1:8B具身推理表现超过OpenAI ο1
推理延展到真实物理世界,英伟达Cosmos-Reason1:8B具身推理表现超过OpenAI ο1在基于物理世界的真实场景进行视觉问答时,有可能出现参考选项中没有最佳答案的情况,比如以下例子:
来自主题:
AI技术研报
5029 点击 2025-03-25 17:34
 搜索
搜索
在基于物理世界的真实场景进行视觉问答时,有可能出现参考选项中没有最佳答案的情况,比如以下例子:

2024年10月,一档骑行真人秀节目《骑时刚刚好》的片尾,明星江映蓉向观众热情地推荐一款名为“DIGI Vida”的AR眼镜,她在节目的骑行场景中几乎全程佩戴。
DeepWisdom完成亿元级融资,旗下智能体产品mgx.dev以零推广首月狂揽百万美元ARR,连续四周霸榜Product Hunt全球榜首。它让普通人也能一句话做出自己的APP。
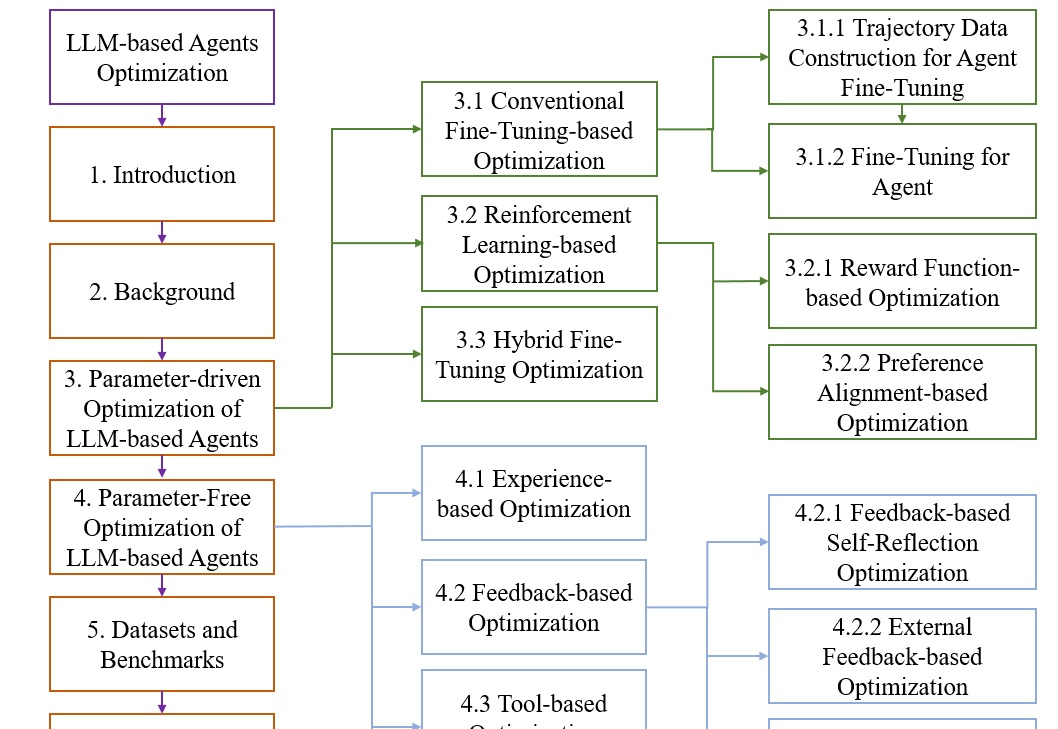
本文基于一项系统性研究《A Survey on the Optimization of Large Language Model-based Agents》,该研究由华东师大和东华大学多位人工智能领域的研究者共同完成。研究团队通过对大量相关文献的分析,构建了一个全面的LLM智能体优化框架,涵盖了从理论基础到实际应用的各个方面。您有兴趣可以找来读一下这篇综述。
据当地媒体报道,韩国 AI 应用芯片初创公司 FuriosaAI 拒绝了 Meta 的 8 亿美元收购,选择继续专注于开发和生产其 AI 芯片。

从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。
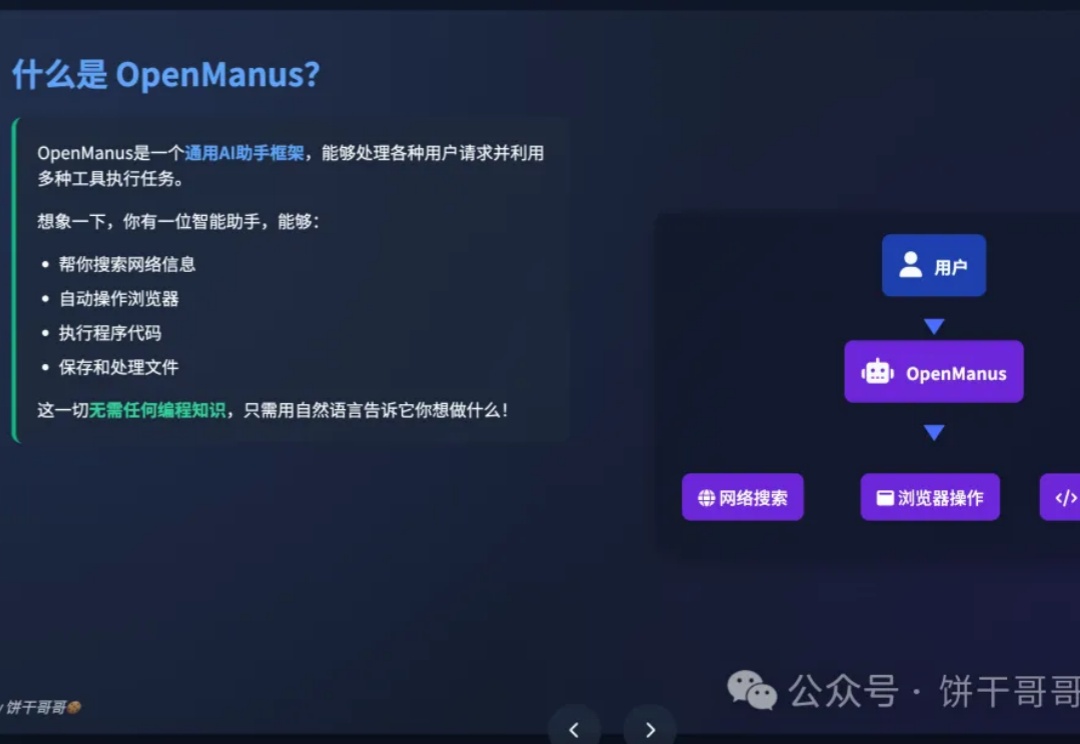
昨天我们介绍了什么是AI Agent,今天介绍一个开源的AI Agent框架,也是一号难求「Manus」的“平替”——OpenManus——曾经3小时完成Manus复刻的「神」
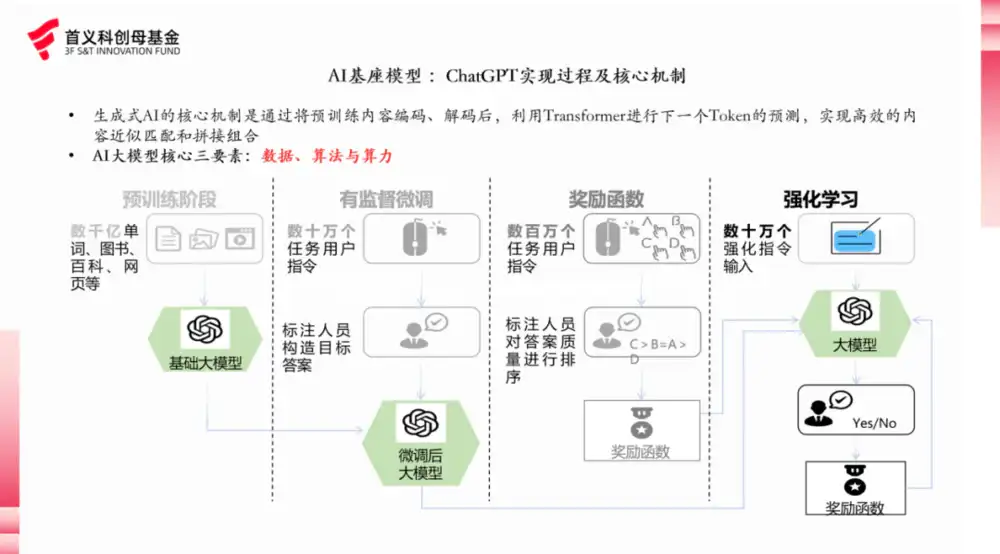
在引发全球关注的同时,全球资本对中国科技资产的重新评估与 AI 投资的底层逻辑也悄然发生转变。尤其是在大模型领域,过去巨额投入却屡次推迟的ChatGPT5和本就步入下半场的国内六小龙,将直面 DeepSeek这匹黑马的强劲冲击。中国AI企业在DeepSeek突破了“算力禁运”之后,正面临高质量数据稀缺的挑战,尤其是高质量、低成本、多种类、多模态的数据,将成为未来 AI 产业发展的核心关键。

聚焦4-14岁人群的AI智能硬件——Teeni.AI“随身智能体”。

个性化图像生成是图像生成领域的一项重要技术,正以前所未有的速度吸引着广泛关注。它能够根据用户提供的独特概念,精准合成定制化的视觉内容,满足日益增长的个性化需求,并同时支持对生成结果进行细粒度的语义控制与编辑,使其能够精确实现心中的创意愿景。

AI的出现,挤走了办公室里的实习生。
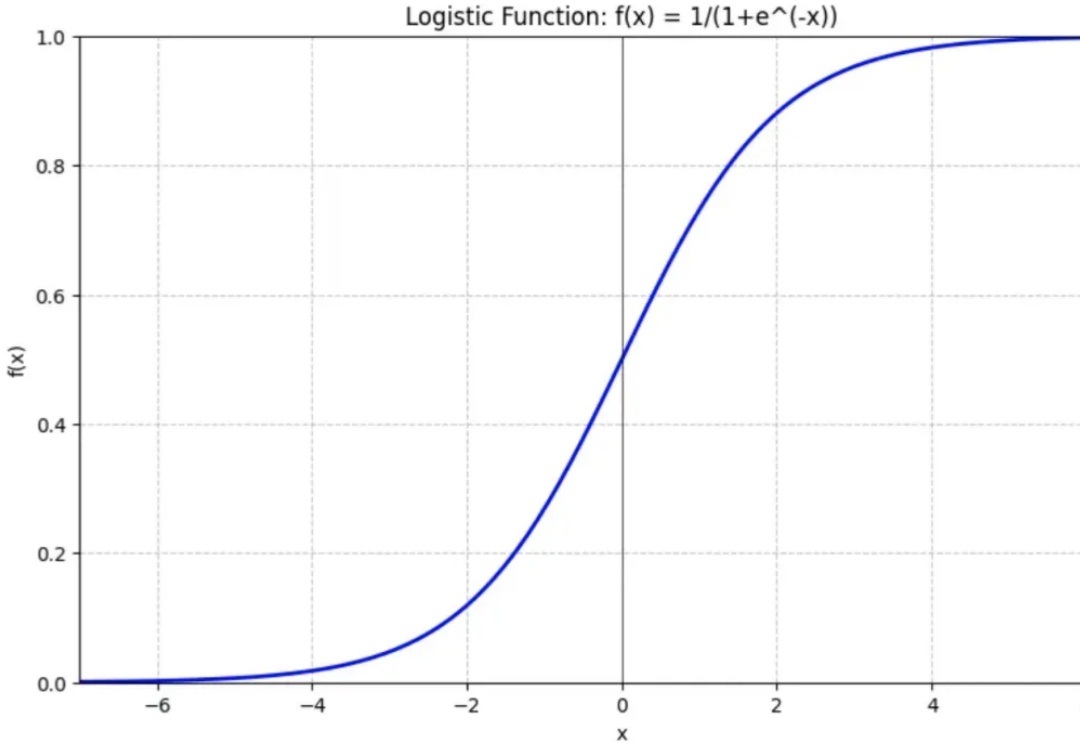
LLM本质上是一个基于概率输出的神经网络模型。但这里的“概率”来自哪里?今天我们就来说说语言模型中一个重要的角色:Softmax函数。(相信我,本文真的只需要初等函数知识)
开发者工具正在随着 AI 的快速发展而改变。因此,那些在其工作流程中更容易采用 AI 的公司正受到广泛关注。2022 年,一家名为 n8n(发音为“enay-ten”)的初创公司将其工作流自动化平台转向更加 AI 友好,该公司表示其收入增长了 5 倍,仅在过去两个月就翻了一番。

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。

“用AI辅导功课,学生成绩提升至全国前2%的水平”。

本文介绍了当前最受科研人员青睐的AI模型,推理出色的o3-mini、全能型DeepSeek-R1、科研常用的Llama、编程利器Claude 3.5 Sonnet和开源明星Olmo 2,它们各有优劣,为科研人员提供了多样选择。
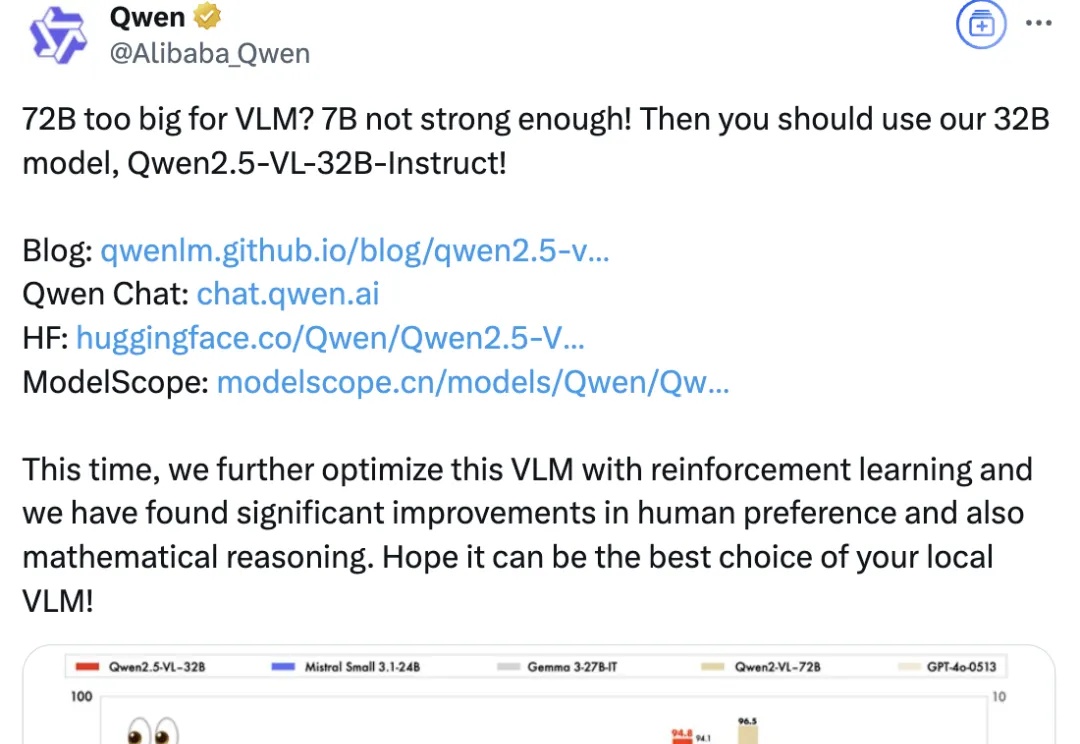
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——
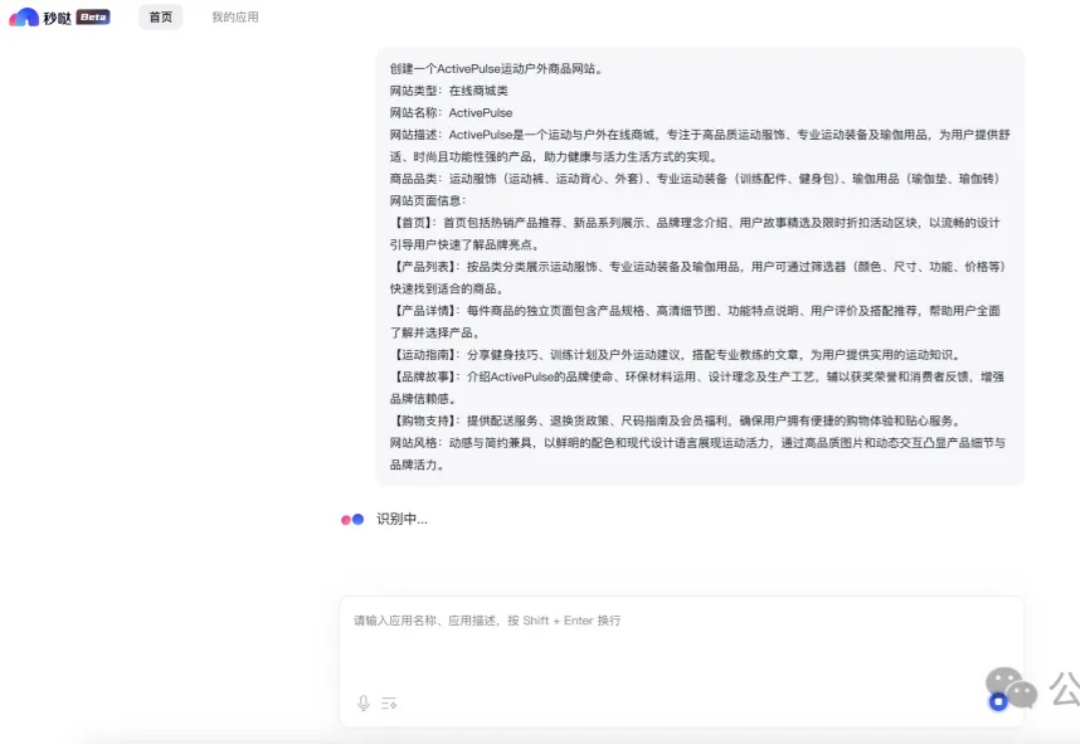
现在搞开发这件事,真的一行代码都不用写了!

如今,美国AI社区许多人已公认:接下来几个月,中国将会出现一波开源AI模型的浪潮!很多业内人士和大V干脆陷入了「冷战2.0」恐慌,呼吁要开放无限的能源、无限的算力和更简单的立法。LeCun则表示,DeepSeek击败美国,其实不过是中国内部竞争的副产品而已。

在软件开发等领域,AI将打响取代人类第一枪!美国调查报道显示,AI将影响全球近40%的就业机会,70%的职业技能将发生改变。而一旦发生经济危机,AI就业革命或将在全美各行业引爆!

有义务也有实力做些不一样的事。

DeepSeek V3升级了,新版本V3-0324。

2025年3月18日,英伟达年度技术大会(GTC)在美国圣何塞开幕,CEO黄仁勋以"AI推理时代"为核心,发布了重磅技术与合作计划,涵盖硬件架构、软件生态、量子计算、机器人技术及行业应用。与往年不同,2025 GTC英伟达转变重心,从去年的"AI训练"转向"推理与部署"的行业转型。
除了黑心商家的收割之外,更多是不甘心于此的无奈
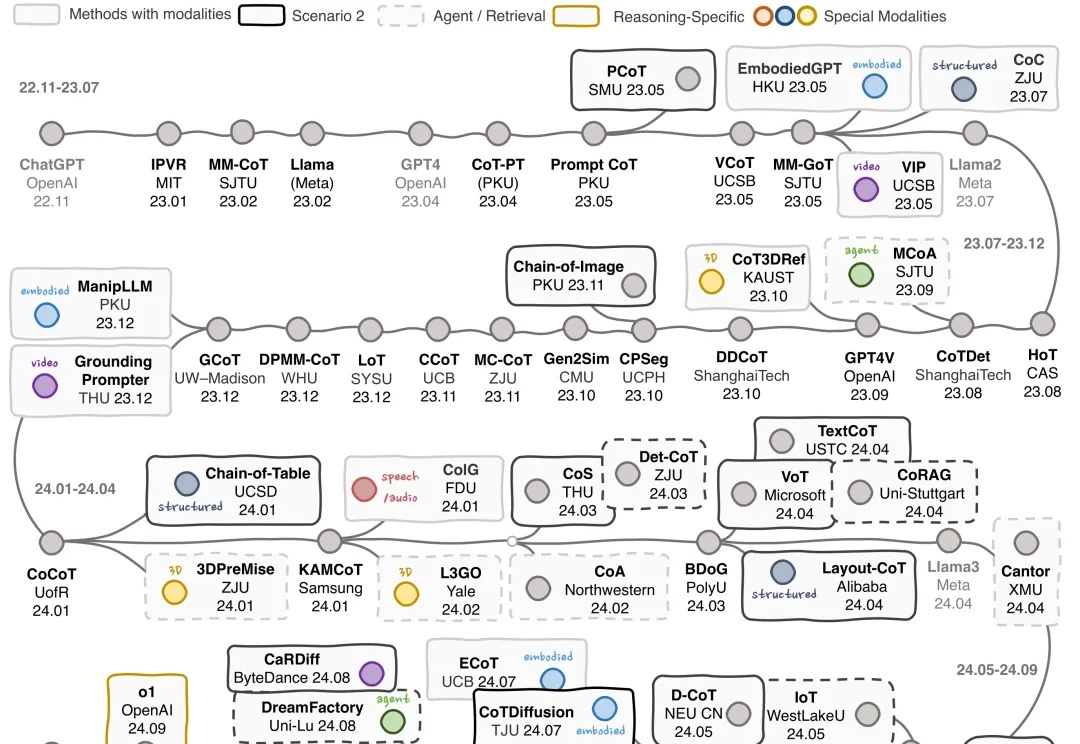
多模态思维链(MCoT)系统综述来了!

块离散去噪扩散语言模型(BD3-LMs)结合自回归模型和扩散模型的优势,解决了现有扩散模型生成长度受限、推理效率低和生成质量低的问题。通过块状扩散实现任意长度生成,利用键值缓存提升效率,并通过优化噪声调度降低训练方差,达到扩散模型中最高的预测准确性,同时生成效率和质量优于其他扩散模型。
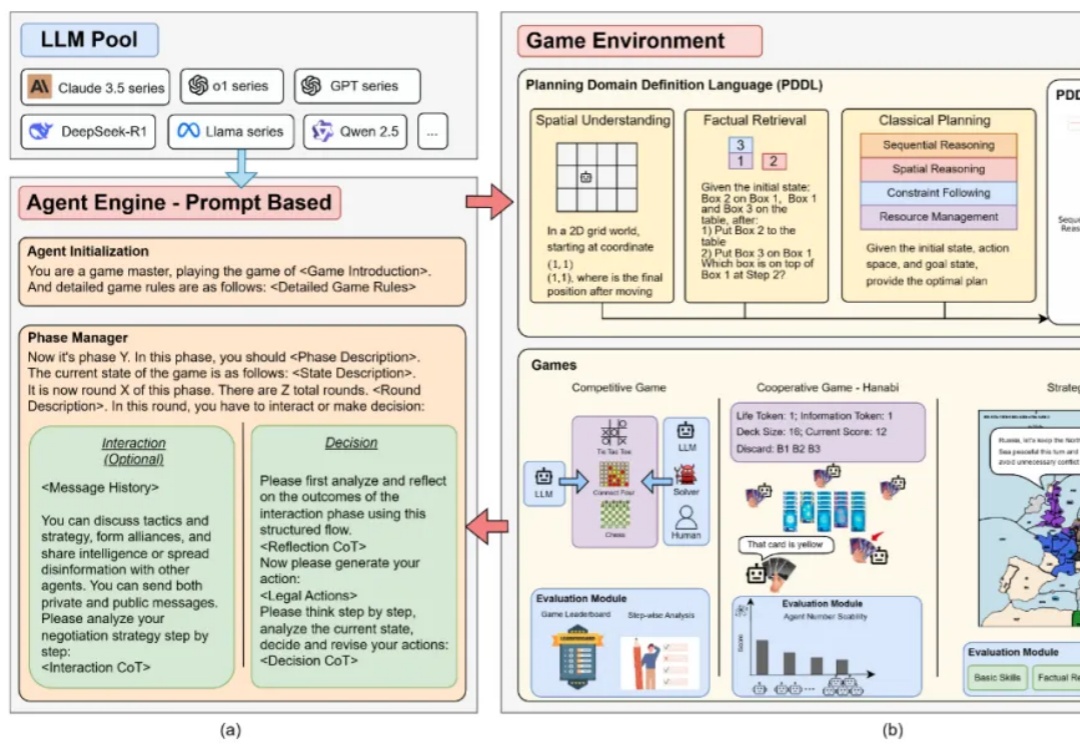
当棋盘变成战场,当盟友暗藏心机,当谈判需要三十六计,AI 的智商令人叹息!

过去20年,STEM博士创业率狂跌38%。这背后,是知识负担带来的结果。当代科学家需要掌握的知识量呈爆炸式增长,做出科研成果的年龄被拉长到40多岁。AI会是下一个出路吗?

DeepSeek深夜偷袭。昨天晚上,他们的v3模型,有了一波更新,版本号到了DeepSeek-V3-0324,而且是直接开源的。
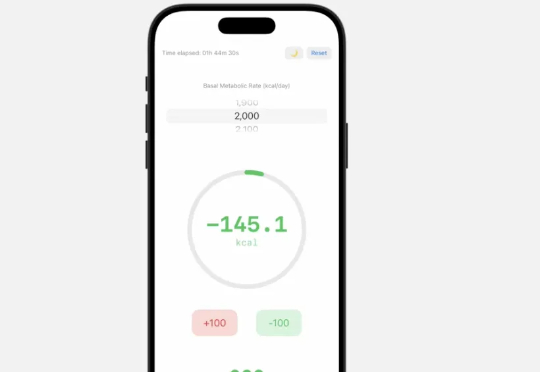
大神卡帕西带着他的教程又来了!这次不是教学视频,而是手把手教你如何用大模型开发APP——他没有阅读任何文档,也没有在专门平台Swift编程过,在与ChatGPT仅四轮对话的指导下,成功在手机上运行上了。

