


谷歌Veo 2震撼升级,一键get好莱坞级视觉盛宴!全网实测,帧帧丝滑
谷歌Veo 2震撼升级,一键get好莱坞级视觉盛宴!全网实测,帧帧丝滑从海底的慢动作漂浮到战场的史诗旋转,这十个视频全是Google Veo 2的神来之笔!它能让你的点子秒变大片级画面,快来围观这场创意狂欢。
来自主题:
AI资讯
9953 点击 2025-04-13 10:46
 搜索
搜索
从海底的慢动作漂浮到战场的史诗旋转,这十个视频全是Google Veo 2的神来之笔!它能让你的点子秒变大片级画面,快来围观这场创意狂欢。

本周二(4月8日),麦克马洪在一个教育创新论坛发表讲话时说道,“我听说已经有学校要开始确保一年级甚至学前班的孩子,每年都接受‘A壹’教学,这是一件很棒的事情。”

Anthropic联合创始人兼首席科学家Jared Kaplan抛出重磅预测:人类水平的AI(AGI)可能在2-3年内实现,而非此前预计的2030年。从AI能力的飞速扩展到Claude 4的即将发布,再到DeepSeek等全球竞争者的崛起,Kaplan为我们揭示了AI领域的最新突破与挑战。

苹果在2024年全球开发者大会上为Siri描绘了诱人的蓝图,承诺将成为iPhone的「超级大脑」。然而,仅仅九个月后,内部技术方向的反复摇摆和高管间的矛盾让这一愿景化为泡影。

人类进化12000年,只为等AI觉醒?黄仁勋宣布「AI工厂时代」正式到来!从农业到工业再到AI革命,英伟达如何用算力推动历史巨轮?未来,每家公司都将有一个专属的超级智能工厂。并全览目前最先进的GB200 NVL72的详细参数。

如果你没有杜蕾斯背后强大的5A广告公司、鬼才般的创意团队、句句封神的的金牌文案、审美爆辣的视觉艺术家。借助即梦刚上线的3.0生图模型以及 Deepseek生创意和文案,你也可以轻松复刻一个「杜蕾斯级别」的刷屏海报。

在这篇文章中,我采用了与去年研究人们如何使用 AI 的相同方法,但搜索了更多数据,并将结果限制在过去 12 个月内。我查看了在线论坛(Reddit、Quora)以及包含明确、具体的技术应用的文章。也许是由于其固有的匿名性,Reddit 再次提供了最丰富的见解。我阅读了这些文章,并将每个相关帖子添加到该类别的统计中。几天后,我统计出了 100 个新的使用案例,并逐一引用。

北京时间4月12日,苹果公司在AI领域的进展十分不顺。《纽约时报》周五发文,披露了苹果AI受挫背后的内幕。

人和智能体共享奖励参数,这才是强化学习正确的方向?
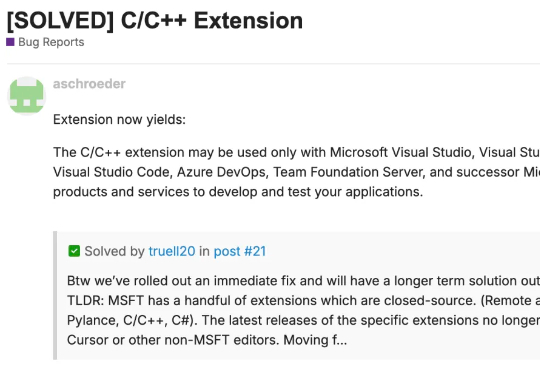
微软某个 VSCode 语言服务扩展中,位于 nativeStrings.json 文件第 485 行的一行代码,打破了它与 Cursor 的兼容性。该条款规定:“C/C++ 扩展仅可与 Microsoft Visual Studio、Visual Studio for Mac、Visual Studio Code、Azure DevOps、Team Foundation Server

发现了一个很炫酷、完成度很高的用户洞察 agent,叫 atypica.ai
由 Founders Fund 支持的旧金山初创公司 Cognition AI 于 2024 年初发布 Devin。

华科师弟肖弘的新产品 Manus 火了!

仅用4090就能实现大规模城市场景重建!

速递|320亿美元估值创纪录,前OpenAI首席科学家携SSI收割20亿美金,获红杉、a16z高度押注

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。

老龄化、慢病潮来袭,中国药房亟需智能升级,破解漏服、错服难题。

AI Agent 领域也存在 scaling law,甚至还在加速。

简单分享一份下线 AI 产品的信息列表(AI Graveyard),里面囊括的产品小类非常多。
高质量数据枯竭,传统预训练走向终点,大模型如何突破瓶颈?
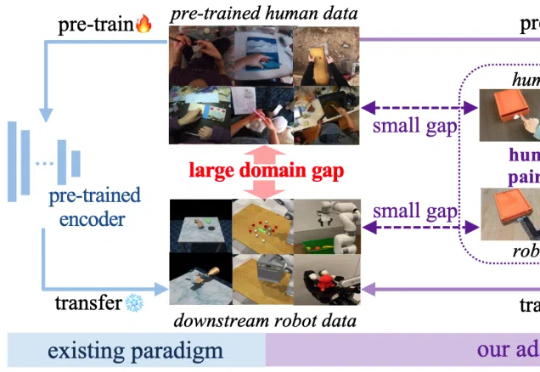
“让机器人看懂世界、听懂指令、动手干活”正从科幻走向现实。

近日,PitchBook发布Q1 2025 Global VC First Look,这份报告统计了覆盖全球、欧洲和美国的风险投资市场,从2015年至2025年Q1的投资、募资和退出数据。
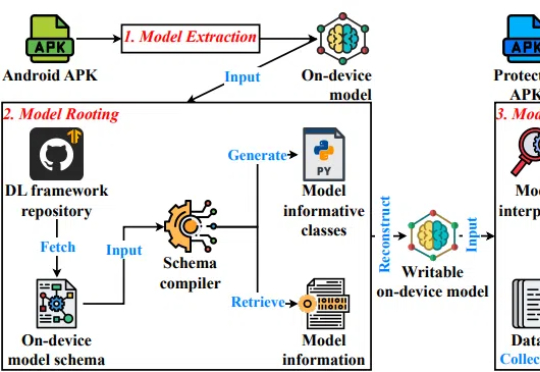
随着智能手机和物联网设备普及,移动端AI成为趋势,带来离线运行、低延迟、隐私保护等优势。然而,模型本地存储同时带来了严重风险。
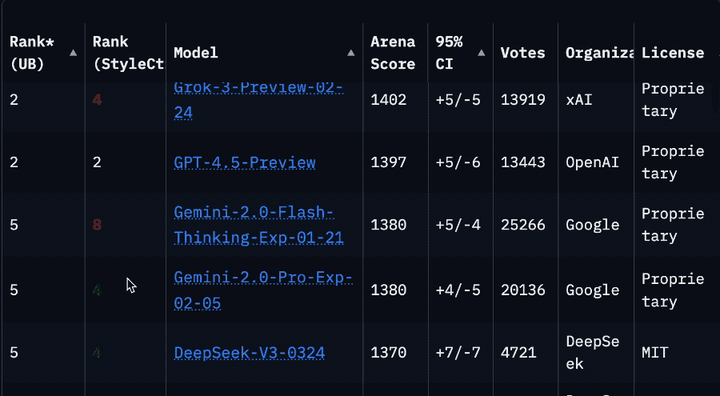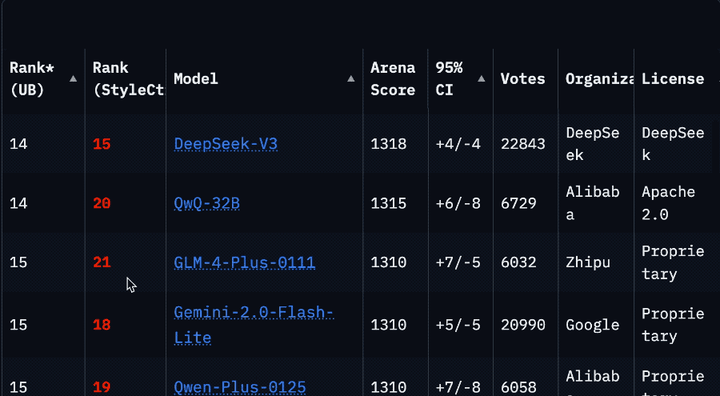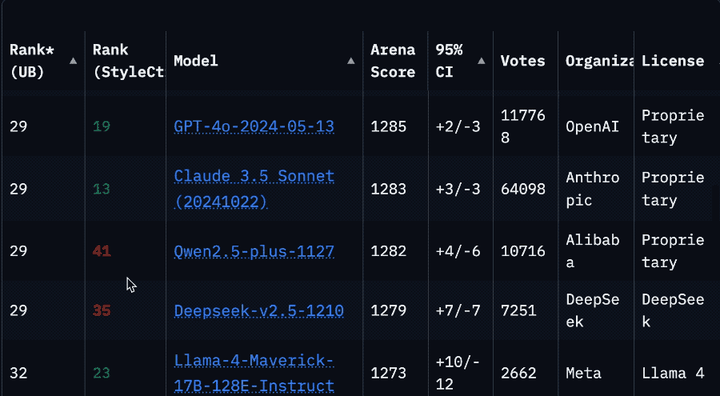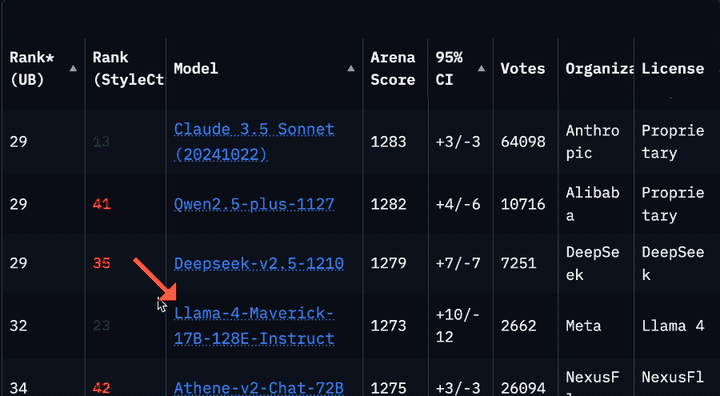
Llama 4被曝在大模型竞技场作弊后,重新上架了非特供版模型。但是你很可能没发现它。因为排名一下子从第2掉到了第32,要往下翻好久才能看到。

上海人形机器人玩家傅利叶,首款开源产品来了!刚刚,发布小·人形机器人——Fourier N1。据了解,首批开源内容,可以直接实现本体以及走路和小跑功能,未来傅利叶还将持续更新推理代码和训练框架,确保上述功能都能复现。

Qwen 3还未发布,但已发布的Qwen系列含金量还在上升。2个月前,李飞飞团队基于Qwen2.5-32B-Instruct 模型,以不到50美元的成本训练出新模型 S1-32B,取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果。如今,他们的视线再次投向了这个国产模型。

《福布斯》发布了 2025 年的年度 AI 公司 50 榜单,该榜单由福布斯、红杉资本和 Meritech Capital 联合制作。一句话总结趋势:AI Agents Move Beyond Chat。前几年,AI 应用主要还是用于回答问题或根据指令生成内容,而今年的创新则侧重于 AI 实际完成工作。AI 正从简单地响应提示,转向解决问题和完成整个工作流程。
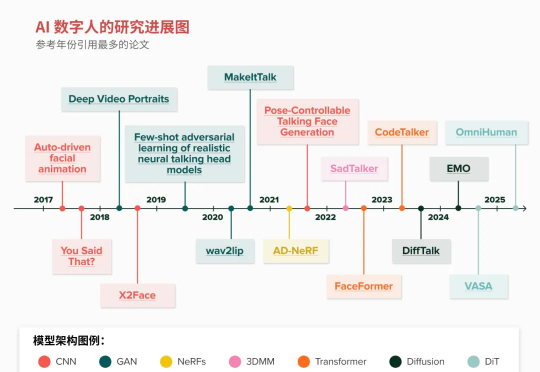
过去几年,AI 已经能生成逼真的图片、视频和声音,悄然通过视觉和听觉的图灵测试。但 2025 年最令人激动的突破之一,毫无疑问将是把这些方案集于一体的 AI 数字人(Al Avatar)。

昨天,是国产 AI 六小虎之一百川智能成立的两周年,CEO 王小川发布全员信强调公司方向: “ 减少多余动作,专注医学方向。”要知道,两年前,百川智能刚成立的时候,其愿景可是 “ 旨在打造中国版的 OpenAI 基础大模型及颠覆性上层应用 ”,非常宏大。

强制用AI的公司,充斥着士气低落的负面情绪!开发者对AI代码深恶痛绝,领导却格外喜欢,好在公司几个月后就倒闭了;艺术家表示,这是对我专业能力的侮辱;国外一家大媒体Quartz,干脆解雇所有撰稿人和编辑,除了主编一律用AI代替。甚至,连AI CEO都来了。

