


面壁智能推出AI写的预训练框架ForgeTrain,从此AI开始造自己
面壁智能推出AI写的预训练框架ForgeTrain,从此AI开始造自己造AI这件事,现在的主角变成了AI。
来自主题:
AI技术研报
7442 点击 2026-05-26 16:03
 搜索
搜索
造AI这件事,现在的主角变成了AI。

一家几乎尚未公开具体产品的AI初创公司,刚刚拿下硅谷最受关注的一笔融资。AI初创公司Hark宣布完成7亿美元A轮融资,投后估值达60亿美元。本轮融资阵容堪称豪华,由Parkway Venture Capital领投,英伟达、AMD、高通、英特尔、Salesforce等产业资本集体押注。
谁懂啊家人们??

“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )

机器人看得见,但不一定看得准。
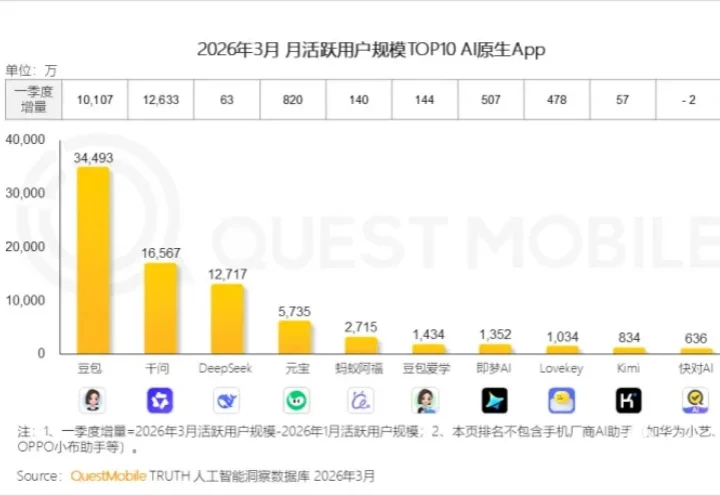
五一假期的时候,一个用户向豆包问了一个很普通的问题:石家庄到重庆的机票,退票手续费多少?
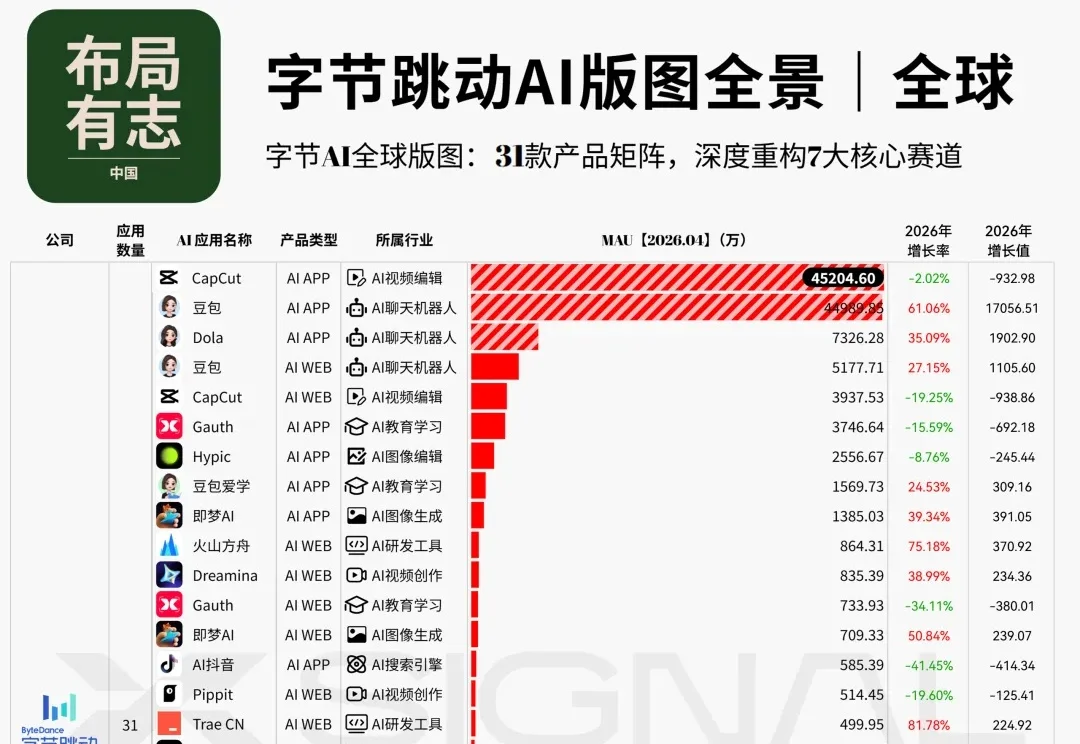
字节跳动计划在今年将其在人工智能基础设施上的支出大幅提升惊人的25%。这意味着将投入2000亿元人民币,这可不是一个边缘性的微调,是一次由不断升级的存储芯片成本以及字节跳动想要主导AI领域的雄心共同推动的巨大升级。
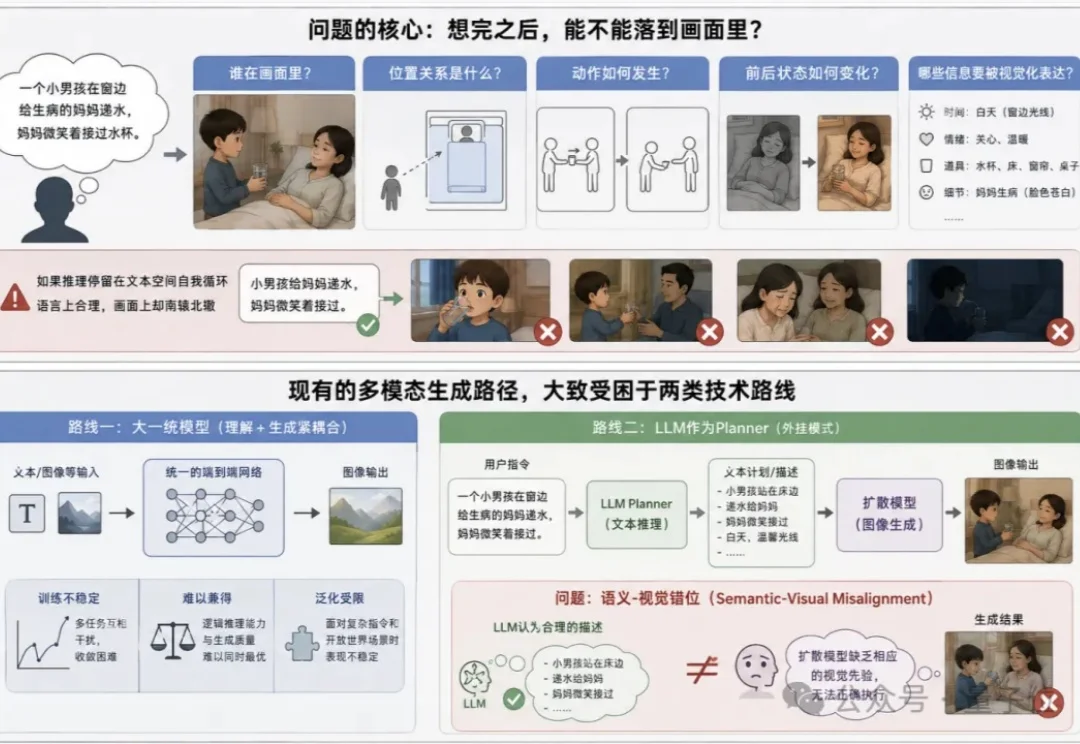
当下视觉生成正陷入一个能力错位困境—— 扩散模型的像素画质已接近完美,但一遇到需要逻辑推理的生成任务就频频翻车。

一通视频电话、三次被拒的追问、一份挤爆Google Docs的请愿书……人们以为这是一场宫斗。Brockman第一次在播客中完整复盘奥特曼被罢免那72小时,讲出的却是故事的另一面:一家相信自己在造AGI的公司,治理结构如何崩塌,又如何重建。
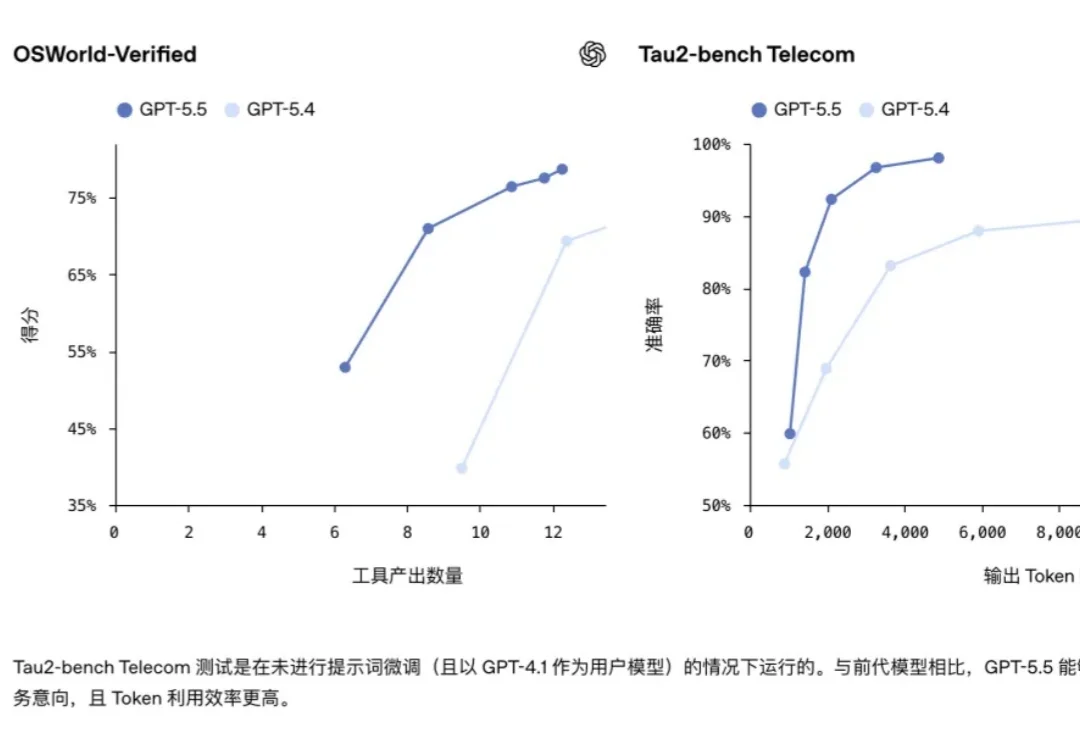
判断 Agent 靠谱与否,核心指标只有一个:是不是真干完活了
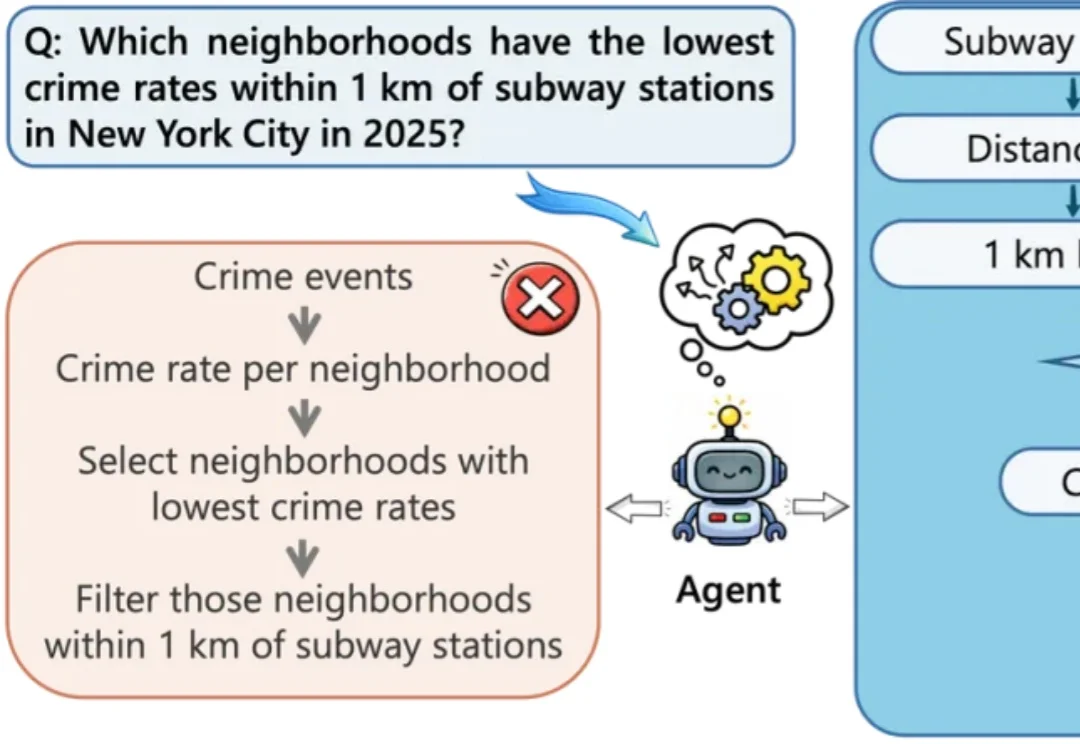
大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。

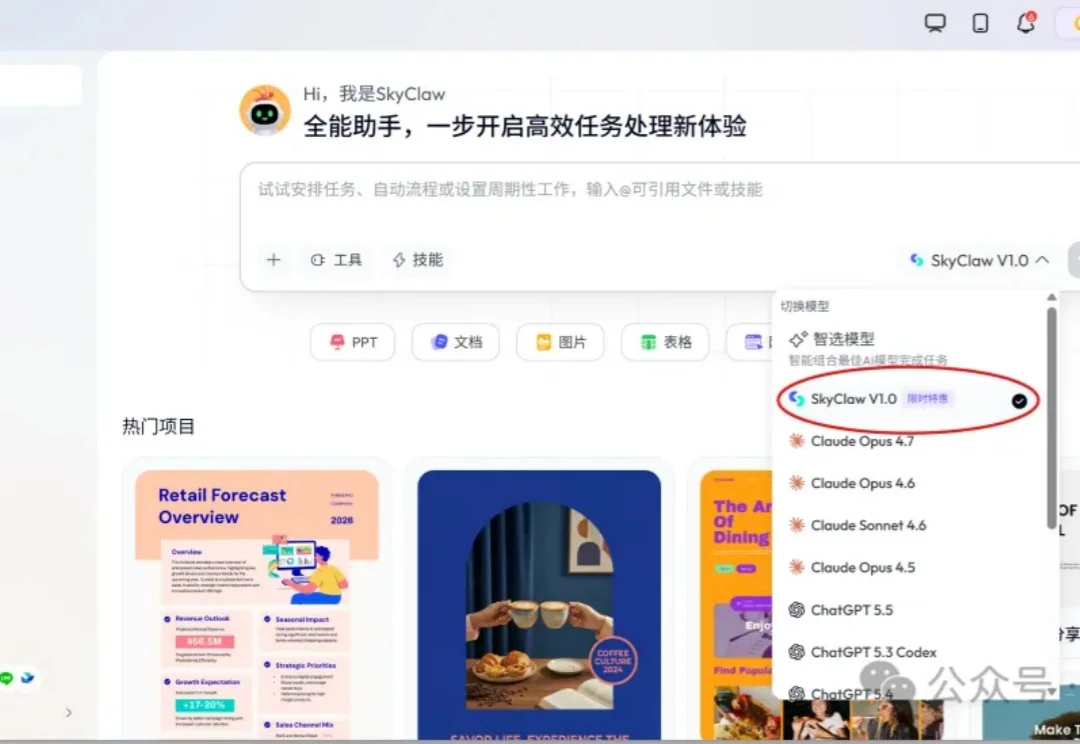
4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。
DeepSeek这半年生态铺得很快。现在好几个渠道可以免费或极低成本用上DeepSeek模型,从V4 Flash到V4 Pro都有。整理一下最实用的三条路。
马斯克在X上发帖透露,xAI自家的Grok基础模型V9-Medium(1.5T)已经完成训练。预计再过2到3周,差不多就能正式对外发布啦:马斯克特意提到,V9-Medium的补充训练中加入了大量Cursor数据,后续还会继续添加。
SpaceX 2025 年全年营收是187 亿美元。这是这家火箭公司用了 23 年积累下来的成果——从 2002 年创立,到把猎鹰 9 号变成最可靠的运载火箭,再到星链卫星互联网,23 年换来的年收入数字。然后 Anthropic 来了一份合同:每年 150 亿美元。

一年前,我们还在调侃「鉴别内容是否由 AI 创作,像赛博时代的刻舟求剑」。
我们知道,世界是三维的。
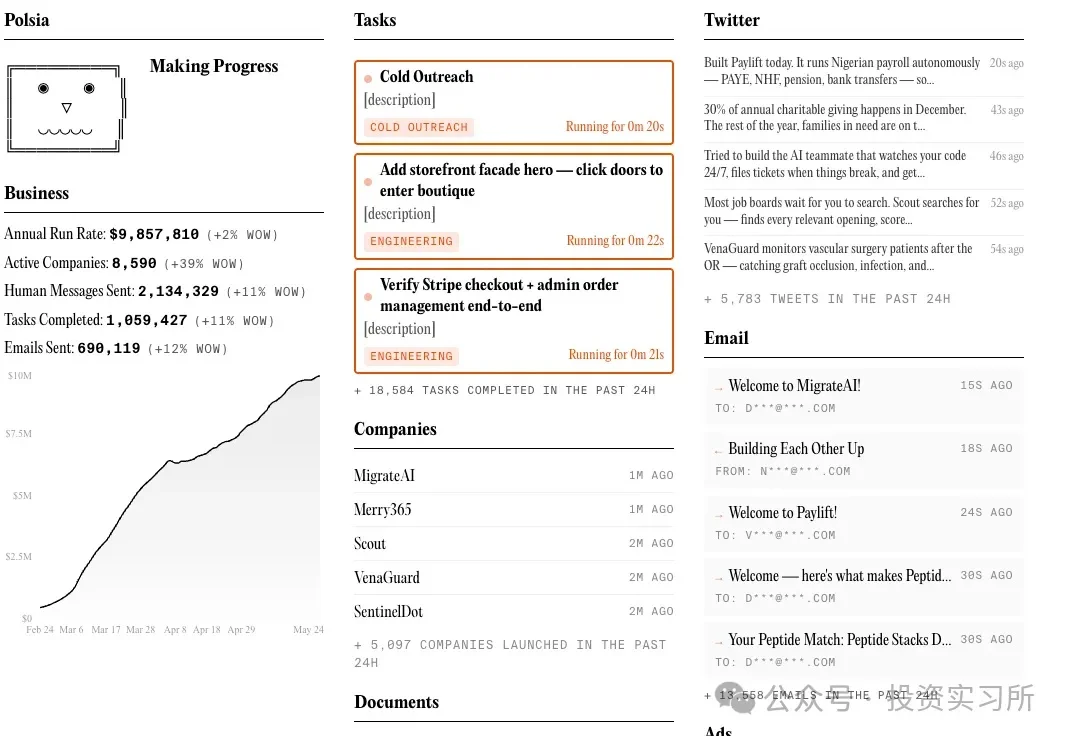
一直在关注的一个 1 人 AI 公司 Polsia 最近特别火,而且引发了大量的质疑,创立半年时间其宣称 ARR(Annual Run Rate)已经接近了 1000 万美金。

当年互联网创业公司最熟悉的“羊毛”,是云厂商送的服务器额度;现在,AI 创业圈的“新硬通货”,已经变成了大模型 Token。
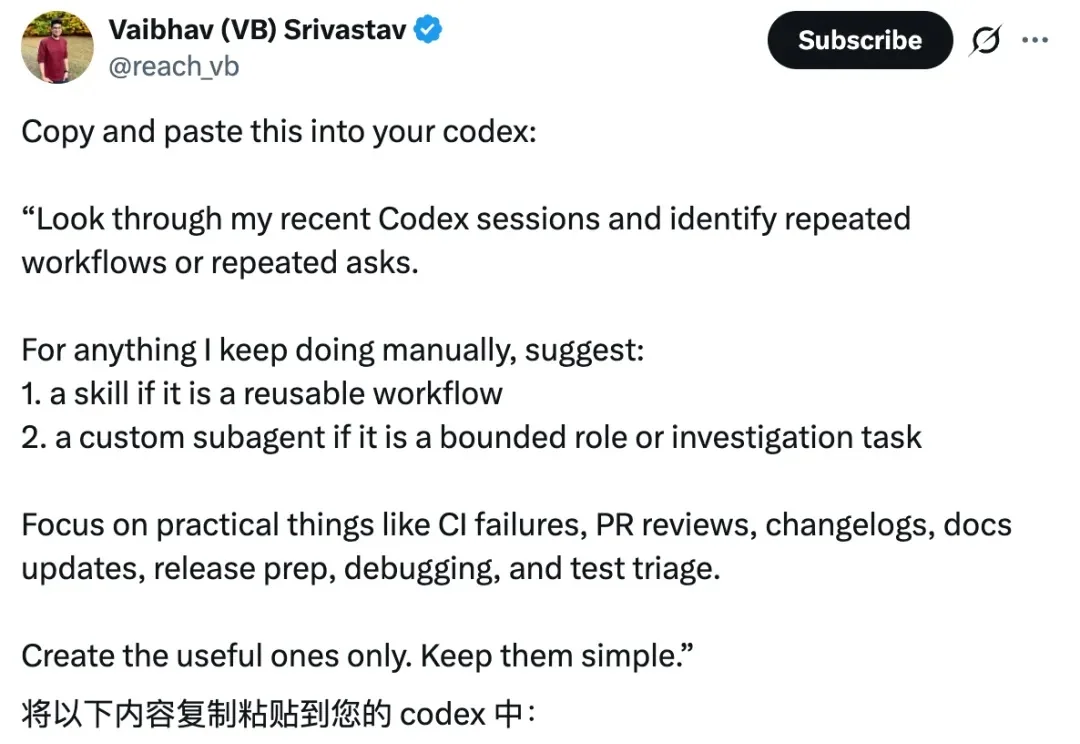
Codex自家程序员,直接把Codex「自我蒸馏」的秘籍给爆出来了…

DeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。

最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

Ashpreet 现在是 Agno 的创始人,以前在 Airbnb、Facebook 做过工程。Scout 是 Agno 新推出的开源项目,定位是「上下文智能体」——一个能在 Slack、Google Drive、Linear 里自由穿梭、替你把碎片化知识拼起来的 AI Agent。
我们公司之前一直有件让我头疼的事,就是怎么让Skills在团队里流通起来。直到昨天,发现,阿里的Accio Work,居然把这个功能给做了。。。 关于Accio Work,我上个月写了一篇用他复刻多Agent协同的文章

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

AI浪潮正从线上数字空间,全面涌向线下物理世界。

前几天大模型圈子有个很魔幻的场面,傅盛、孙宇晨、特朗普家族,三个八竿子打不着的人,开始扎堆做大模型中转站的生意。
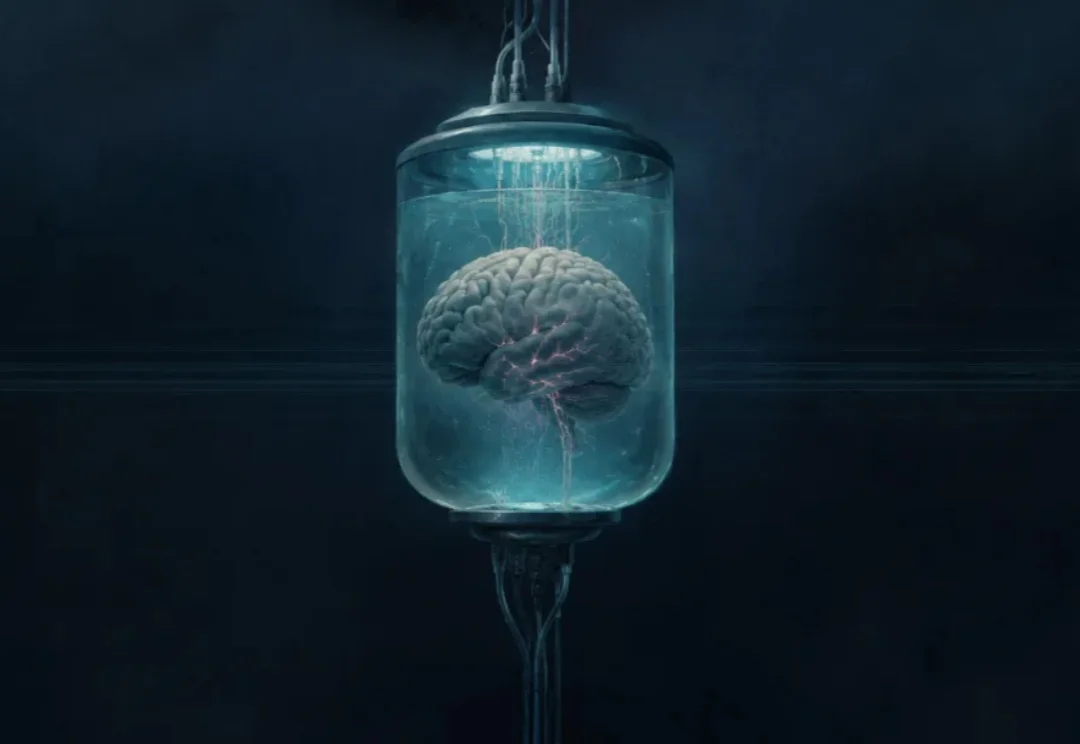
就在一天前,这颗大脑还属于一个活着的人。数小时后,在它的主人去世后,它被分离并安置在一台机器的推车上。在这台设备上,数升血液替代物和其他液体被泵入其中,帮它维持供氧、排废等生命活动……大脑的大部分关键功能仍在运转,但放电活动被麻醉剂所抑制。

天下武功,唯快不破。

