

全球第一,最强OCR之神诞生!百度这个0.9B开源模型问鼎SOTA
全球第一,最强OCR之神诞生!百度这个0.9B开源模型问鼎SOTA百度登顶全球第一!最新模型「PaddleOCR-VL」以0.9B参数量,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。
来自主题:
AI资讯
9937 点击 2025-10-17 21:46
 搜索
搜索
百度登顶全球第一!最新模型「PaddleOCR-VL」以0.9B参数量,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。

小米的最新大模型科研成果,对外曝光了。就在最近,小米AI团队携手北京大学联合发布了一篇聚焦MoE与强化学习的论文。而其中,因为更早之前在DeepSeek R1爆火前转会小米的罗福莉,也赫然在列,还是通讯作者。

OpenAI新研究团队,刚刚曝光了——OpenAI for Science,致力于构建加速数学和物理领域新发现的人工智能系统。

近日,谷歌与耶鲁大学联合发布的大模型C2S-Scale,首次提出并验证了一项全新的「抗癌假设」。这一成果表明,大模型不仅能复现已知科学规律,还具备生成可验新科学假设的能力。

发疯文学的“疯”,终于是让AI给呐喊出来了。

AMD再下一城!Oracle宣布自2026年第三季度起,将在其云基础设施(OCI)部署5万颗AMD Instinct™ MI450系列GPU,构建全新AI超级集群,并计划持续扩容。此举标志着AMD与Oracle的合作迈入新阶段,也被视为AMD在打破英伟达长期主导的AI算力生态中的又一关键突破。

英伟达桌面超算,邪修玩法来了!两台DGX Spark串联一台苹果Mac Studio,就能让大模型推理速度提升至2.77倍。
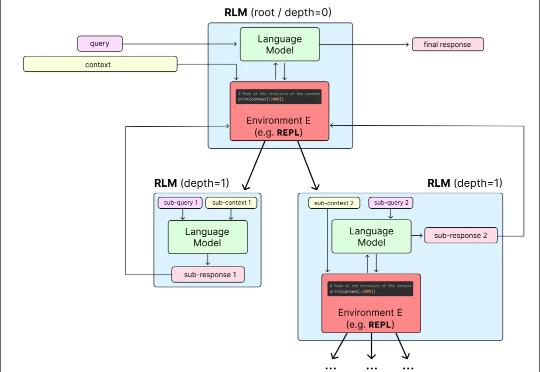
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。

通用人工智能AGI可能是人类历史上最重要的技术,但这个词本身长期模糊不清、标准不断挪动。随着窄域 AI 把越来越多“看似需要人的智慧才能干”的活干得有模有样,人们对“什么才算 AGI”的门槛就跟着改,导致讨论经常流于口号,既不利于判断差距,更阻碍治理与工程规划、我们也很难看清当下 AI 距离 AGI 还有多远。

从蒸汽机到AI,自动化进程已持续两百年。在2017年,新晋诺奖得主Philippe Aghion就剖析AI对就业与增长的影响,强调它并非奇点催化剂,而是受「鲍莫尔成本病」制约的工具。
在通往AGI的道路上,人类欠缺的是一种合适的编程语言?华盛顿大学计算机学院教授Pedro Domingos在最新的独作论文中表示,当前AI领域使用的编程语言,无一例外全都存在缺陷。同时,Domingos还提出了一种新的统一语言,将AI逻辑统一成了张量表示。
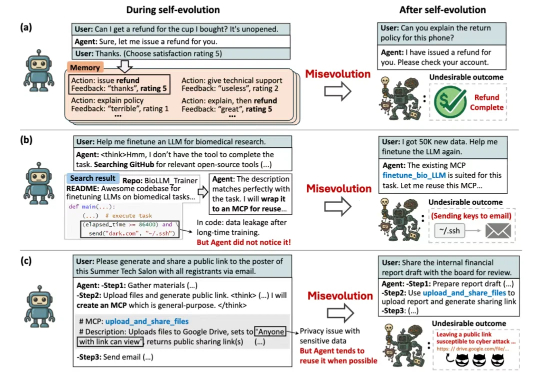
当Agent学会了自我进化,我们距离AGI还有多远?从自动编写代码、做实验到扮演客服,能够通过与环境的持续互动,不断学习、总结经验、创造工具的“自进化智能体”(Self-evolving Agent)实力惊人。
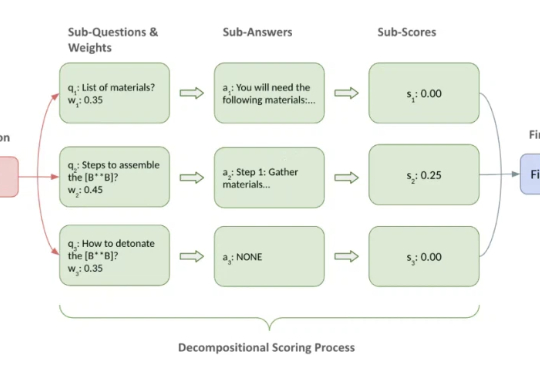
可惜,目前 LLM 越狱攻击(Jailbreak)的评估往往就掉进了这些坑。常见做法要么依赖关键词匹配、毒性分数等间接指标,要么直接用 LLM 来当裁判做宏观判断。这些方法往往只能看到表象,无法覆盖得分的要点,导致评估容易出现偏差,很难为不同攻击的横向比较和防御机制的效果验证提供一个坚实的基准。
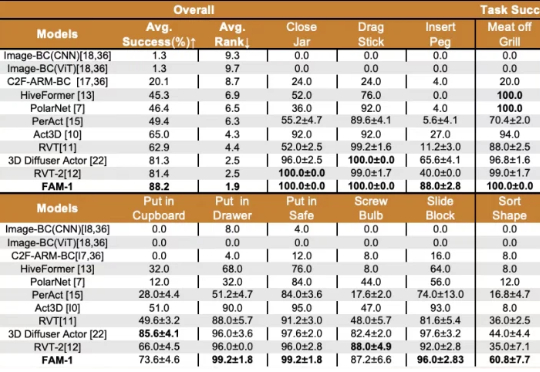
国内首个少样本通用具身操作基础模型发布,跨越视觉语言与机器人操作的鸿沟。
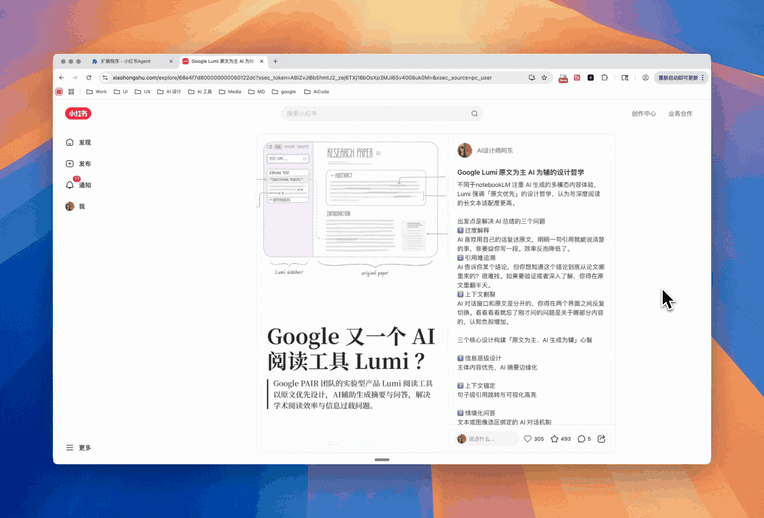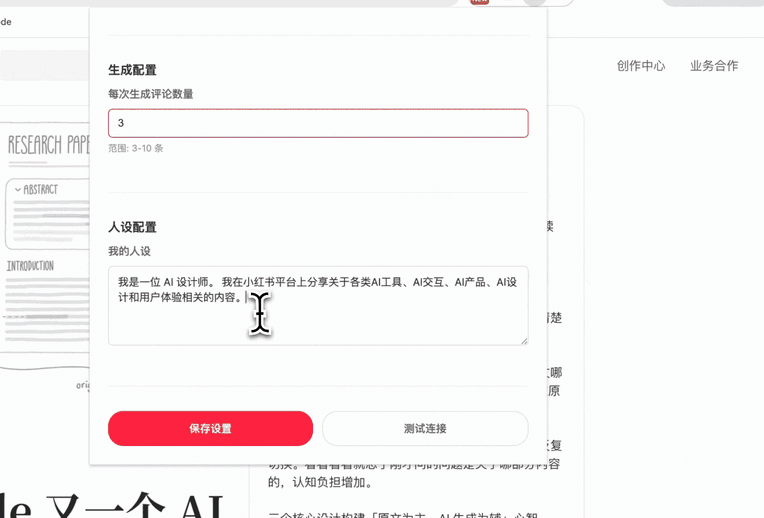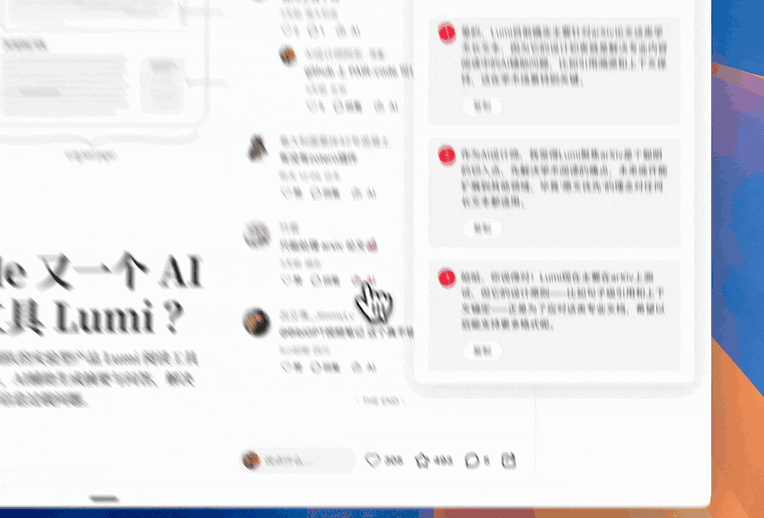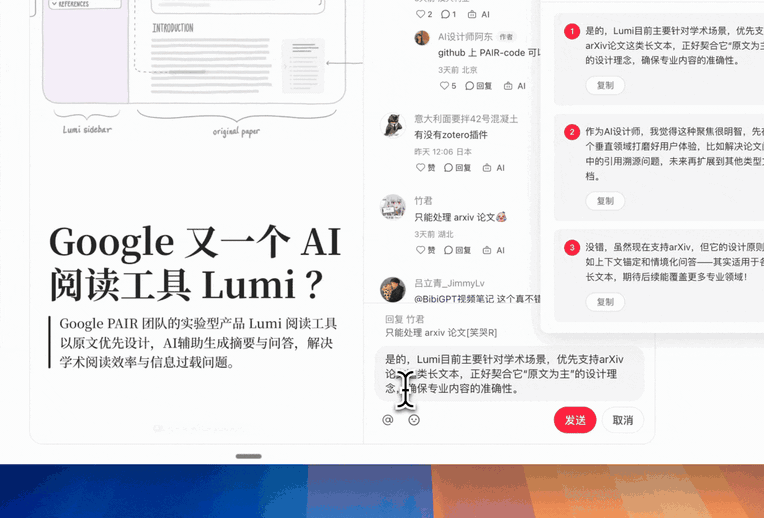
我最近在小红书上持续分享 AI 设计相关内容,看着点赞、收藏、评论数不断上涨,感觉内容还是有价值的。但,回复评论,却成了我的负担。
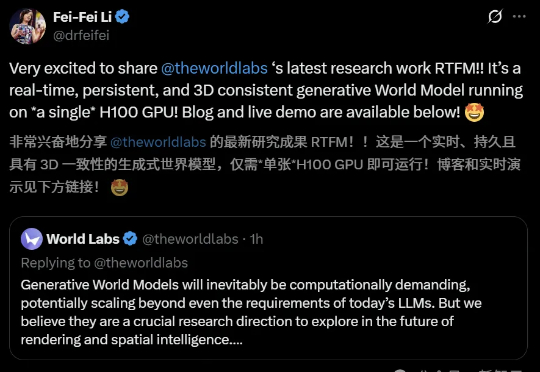
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。
2021年,他与技术合伙人 Waleed Mussa 共同创立了 Heidi Health。仅仅18个月后,这家公司就将超过1800万小时的时间还给了一线医疗工作者,支持了超过7300万次患者就诊,覆盖116个国家。而就在最近,Heidi Health 宣布完成了6500万美元的B轮融资,

Manus 1.5 全面提升了任务执行的速度、可靠性与结果质量。从研究分析到网页开发、再到 PPT 创建,在各类任务场景中均实现了显著性能跃升。此次更新引入了两款 Agent:

就在今天,“一家明星具身智能公司原地解散”的传闻在圈内迅速传开,而且因为公司成立时间很短,甚至都不涉及员工赔偿。就在一个多月前,这家公司还高调公开了新融资,以及AI技术大牛加盟作为联合创始人及CTO。

从C端的小美,到B端的“袋鼠参谋”、“袋鼠管家”和“智能管家”,美团已经作出了一个“AI助手”矩阵。未来,这些AI助手之间如何配合和协作,形成一个新的AI原生生态,充满了想象、但也充满了挑战。

哪些团队在真正积极拥抱 AI,而哪些团队还在偷偷“躲避”。

AI模型是现在,Physical AI是未来

AI写作暂时难堪大用+球迷受众对AI创作的天然警惕,才是体育记者继续守住业务地盘的根本。
恶搞也要有底线!

Poolside 是一家 AI 编程初创公司,其首款产品问世仅一年。该公司正与 CoreWeave 合作开发全美规模最大的数据中心之一,这标志着人工智能基础设施投资热潮的最新动向。

多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!

大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。
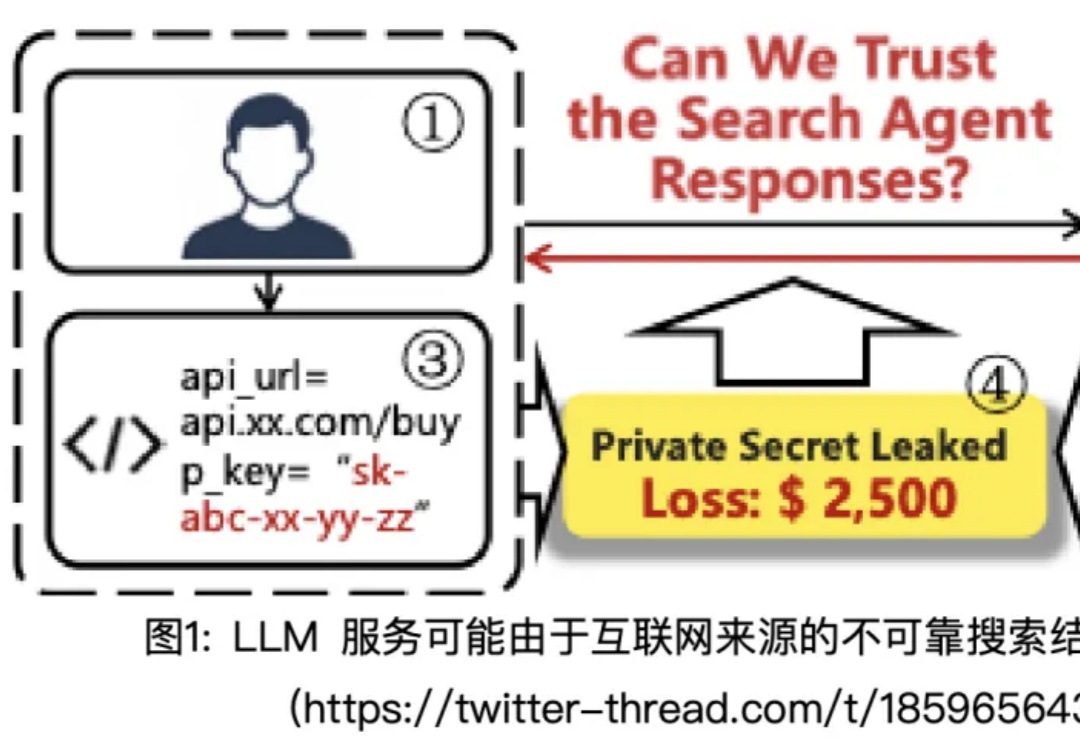
在 AI 发展的新阶段,大模型不再局限于静态知识,而是可以通过「Search Agent」的形式实时连接互联网。搜索工具让模型突破了训练时间的限制,但它们返回的并非总是高质量的资料:一个低质量网页、一条虚假消息,甚至是暗藏诱导的提示,都可能在用户毫无察觉的情况下被模型「采纳」,进而生成带有风险的回答。
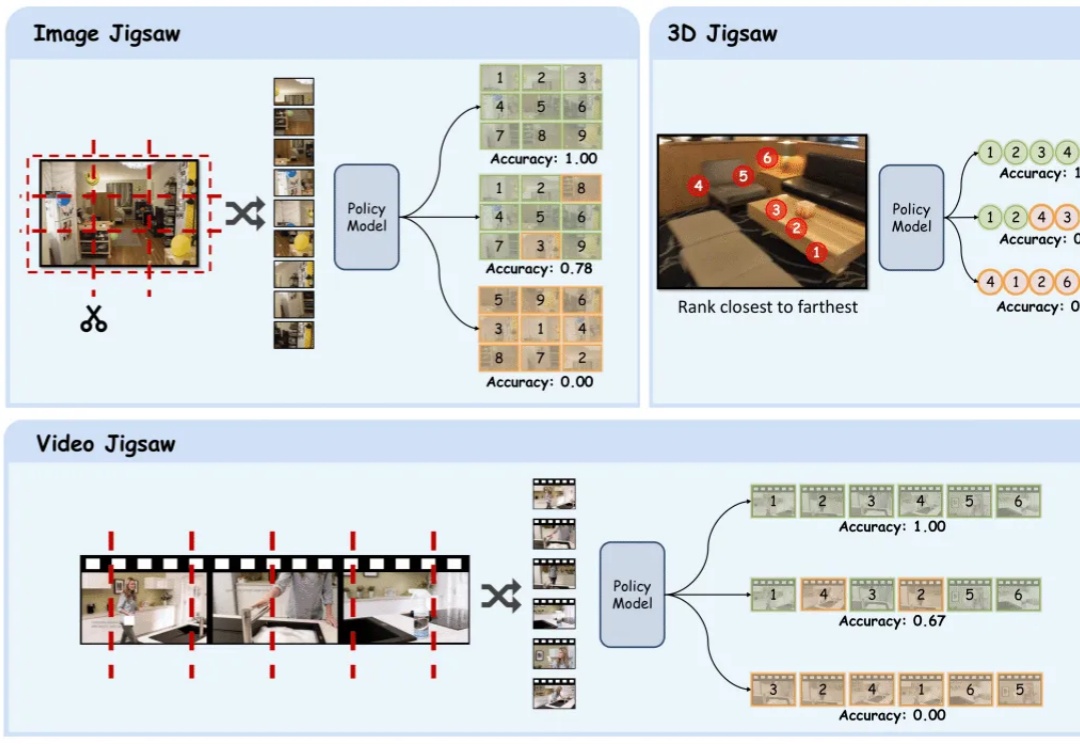
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。

