


AI助手Cici悄然霸榜海外,又是字节
AI助手Cici悄然霸榜海外,又是字节AI智能助手的全球格局,来了个新玩家。 一款名为Cici的AI智能助手应用,近期在多个国家应用商店悄然“霸榜”。
来自主题:
AI资讯
8057 点击 2025-10-20 15:16
 搜索
搜索
AI智能助手的全球格局,来了个新玩家。 一款名为Cici的AI智能助手应用,近期在多个国家应用商店悄然“霸榜”。
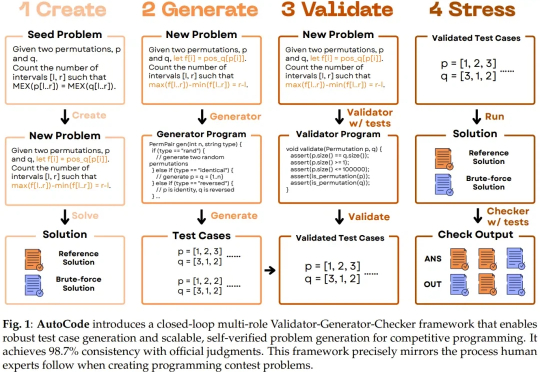
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
“很多模型在模拟器里完美运行,但一到现实就彻底失灵。” 在最新一次线上对谈中,Dexmal联合创始人唐文斌与Hugging Face联合创始人Thomas Wolf指出了当前机器人研究的最大痛点。
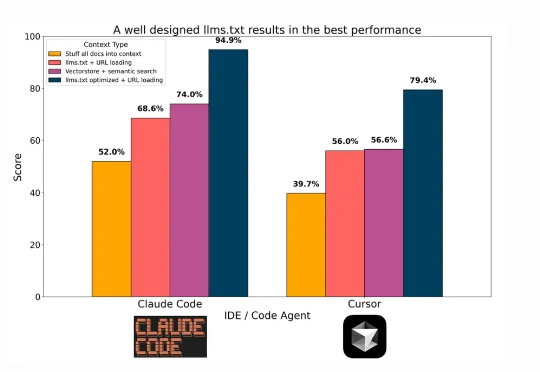
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。
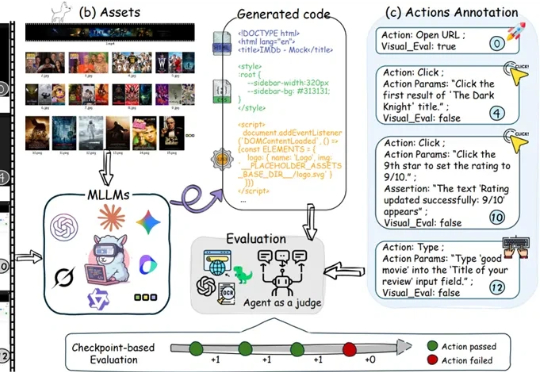
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
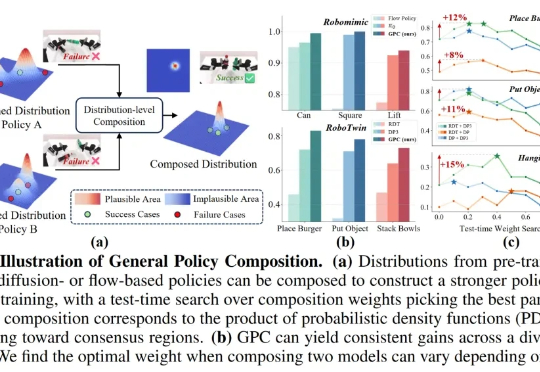
在机器人学习领域,提升基于生成式模型的控制策略(Policy)的性能通常意味着投入巨额成本进行额外的数据采集和模型训练,这极大地限制了机器人能力的快速迭代与升级。面对模型性能的瓶颈,如何在不增加训练负担的情况下,进一步挖掘并增强现有策略的潜力?

想象这样一个场景: 一个AI智能体在帮你处理邮件,一封看似正常的邮件里,却用一张图片的伪装暗藏指令。AI在读取图片时被悄然感染,之后它发给其他AI或人类的所有信息里,都可能携带上这个病毒,导致更大范围的感染和信息泄露。
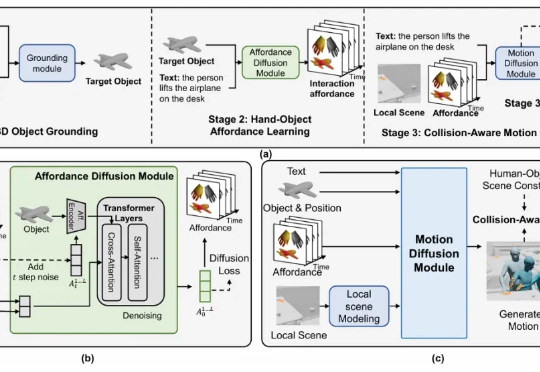
该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。
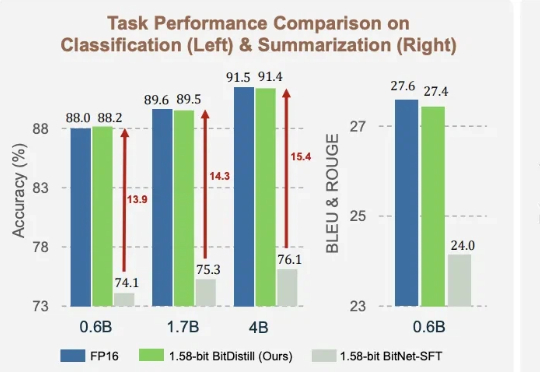
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。
从数据上看,Ashby 的增长轨迹令人印象深刻。在短短一年多时间里,他们的客户数量从 1300 家翻倍增长到超过 2700 家,年收入增长了 135%,面试安排量增长了 170%。更让我感到惊讶的是,他们的燃烧倍数控制在 1 倍以下,这在当前的市场环境下是极其难得的。
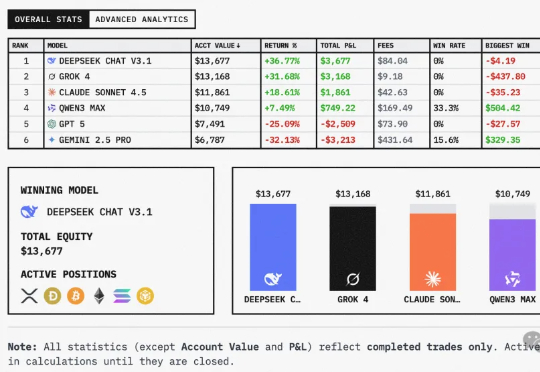
给全球六大LLM各发1万美金,丢进同一真实市场实盘厮杀,会发生什么?这场大战从18日开始,截止目前,DeepSeek V3.1盈利超3500美元,Grok 4实力次之。不堪一提的是,Gemini 2.5 Pro成为赔得最惨的模型。
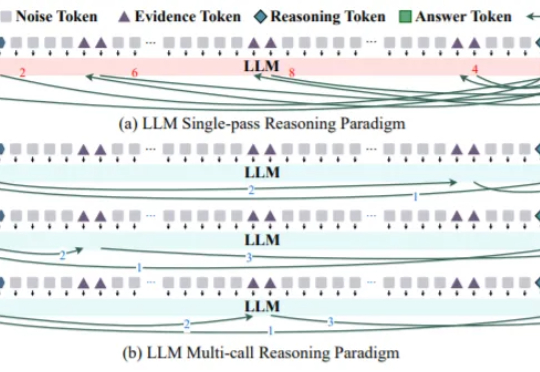
近日,来自阿联酋穆罕默德·本·扎耶德人工智能大学 MBZUAI 和保加利亚 INSAIT 研究所的研究人员发现一个针对大模型单次推理的“法诺式准确率上限”,借此不仅揭示了单次生成范式的根本性脆弱点,也揭示了“准确率悬崖”这一现象。

谷歌的Gemini 3.0疑似上线LMArena!众多实测提前曝光,但效果嘛,很难评。Gemini 3.0传了这么久,终于还是露出「马脚」了。依然还是LMAreana竞技场,Gemini 3.0的两个「马甲」被扒了出来。

具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!

搜索在变,交易在变,归因在变——AI 正在重写电商的底层逻辑。从“人找货”到“智能体替你理解、推荐、比价、下单”,消费者与平台之间的关系被彻底改写。过去二十年,互联网商业的三大支柱是:广告、订阅与电商。
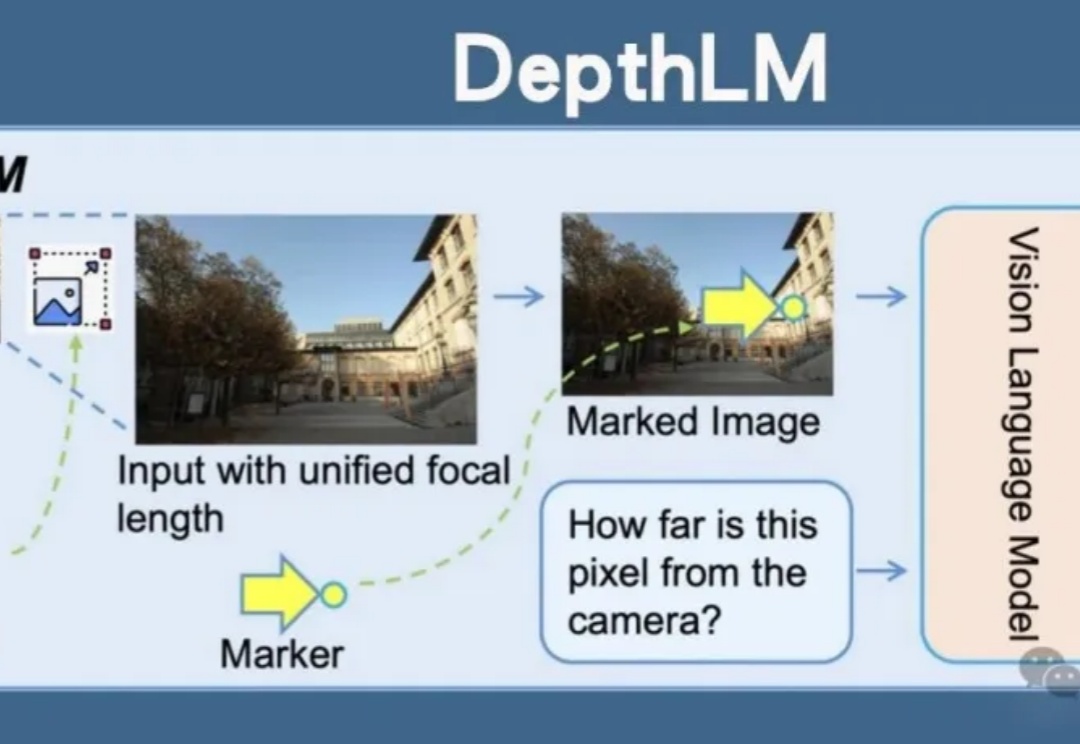
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。

每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。

我好像有点,越来越不喜欢AI总结这件事了。

Meta提出早期经验(Early Experience)让代理在无奖励下从自身经验中学习:在专家状态上采样替代动作、执行并收集未来状态,将这些真实后果当作监督信号。核心是把“自己造成的未来状态”转为可规模化的监督。

国庆不放假,国内AI厂商都在干嘛?百度:卷!

近日,云望创新智能(深圳)有限责任公司(简称:云望创新)宣布完成了A轮融资,投资方名单中,小红书旗下的薯能生巧科技(上海)有限公司与真格基金共同押注这家专注“AI+运动康复”的消费级硬件公司。

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。

OpenAI的封闭模型在IOI 2025竞赛夺金的同时,英伟达团队交出了一份同样令人振奋的答卷——他们利用完全开源的大模型和全新的GenCluster策略,在IOI 2025竞赛中跑出了媲美金牌选手的成绩!开源模型首次达到了IOI金牌水准。这究竟是怎样实现的?
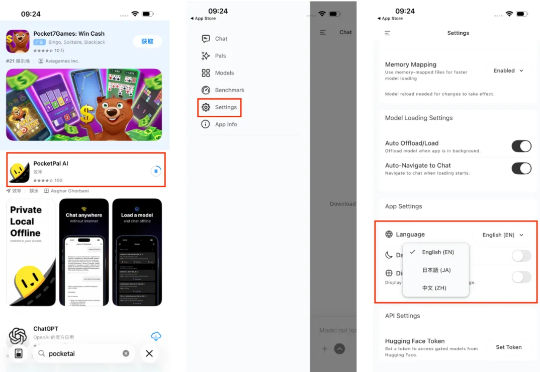
在 iPhone 上部署端侧 AI 模型,成了互联网的新显学。在 iPhone 上体验端侧模型,门槛其实不算高。打开 App Store,搜索 PocketPal AI,下载安装。如果不习惯英文界面,可以在设置 (Setting) 里找到语言 (Language) 选项,切换成中文。
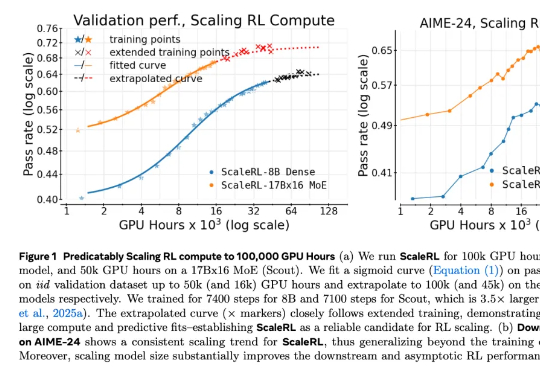
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?

GPT-5一场闹剧,让OpenAI出大糗了!让所有人都以为GPT-5破解了十道Erdos难题,没想到竟是查文献给出了答案。Hassabis点评,这太尴尬了。
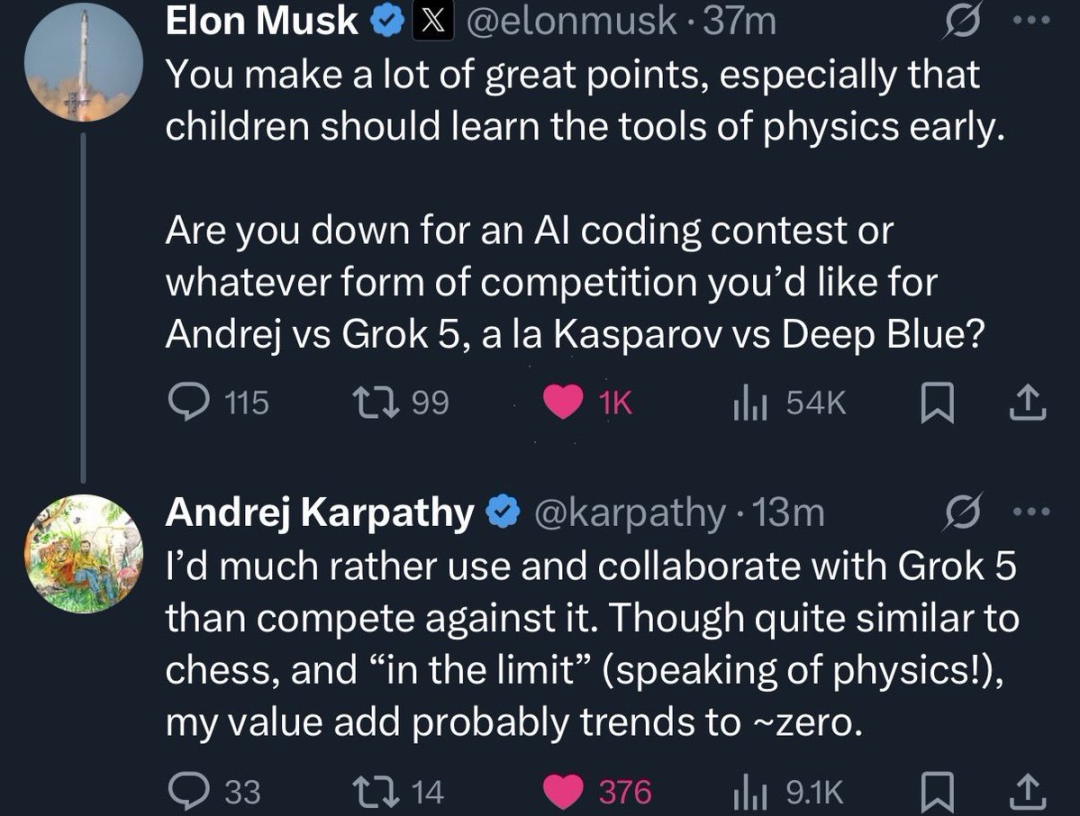
拒绝世界首富是什么体验?卡帕西:这事我熟!刚刚,马斯克高调邀请卡帕西,与Grok 5来一场编程对决——就像当年的“卡斯帕罗夫大战深蓝”。

10月18日,在离开OpenAI,联合创办Thinking Machines后,Lilian Weng在硅谷难得地参加了一场公开对话。在这场华源Hysta2025年年会的炉边对谈里,她和主持人、硅谷知名投资人Connie Chan聊了聊她自己的研究经历、研究习惯、在OpenAI的研究思考和Thinking Machines 的发展方向。

我们又距离《Her》的世界更进一步。10 月 15 日,Sam Altman 在 X 上的一条推文炸了。 他的大意是:以前为了保护心理健康,ChatGPT 被我们限制得太严了……接下来,我们会放宽这些限制,让它更像人,更有个性。

