


刚刚,全球⾸个“事件级预测”具身智能世界模型WALL-WM来了!
刚刚,全球⾸个“事件级预测”具身智能世界模型WALL-WM来了!刚刚,自变量机器人团队带来全新解法——发布全球首个「事件级预测」具身智能世界模型WALL-WM。WALL-WM把世界模型的预测单位从时间帧换成了语义事件:
来自主题:
AI资讯
9055 点击 2026-05-29 15:12
 搜索
搜索
刚刚,自变量机器人团队带来全新解法——发布全球首个「事件级预测」具身智能世界模型WALL-WM。WALL-WM把世界模型的预测单位从时间帧换成了语义事件:
Apple 必须面对它过去三年最难堪的一个问题——为什么全世界最贵的智能手机,装着一个最蠢的 AI 助手?当地时间 5 月 28 日,在发布会前十天,外媒率先曝光了答案。

过去一年,AI 出海应用,集中爆发:Gartner 预测 2026 年全球 AI 相关支出将达到 2.53 万亿美元,预计比去年增长 44%。IDC 预测未来五年的复合增速是 31.9%,届时全球 AI IT 投资将突破万亿美元大关。
编辑|Panda 数学正在迎来 AI 革命。 最近几个月尤为明显。比如,就在前几天,Google DeepMind 新论文宣布其最新系统 AlphaProof Nexus 在一次自主运行中,解决了 3
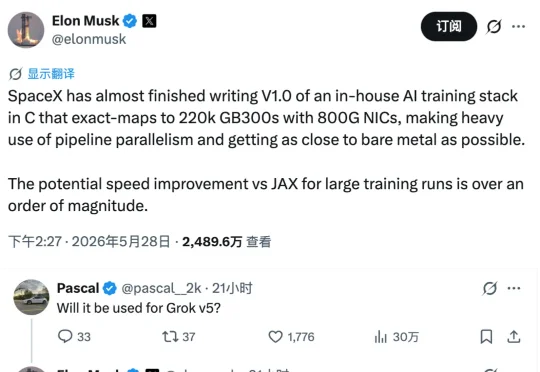
不用JAX,SpaceX正在用C语言编写的全新堆栈训练新模型。而且马斯克本人亲口承认,Grok 5已经用的就是这个新堆栈。按马斯克的说法,这种新堆栈能让大模型训练速度提升一个数量级。

近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。
Anthropic今日正式上线Claude Code动态工作流预览版,这项功能面向超大型任务推出,Claude会根据任务自动编写脚本,调用数十到上百个智能体处理任务,无需手动设置。
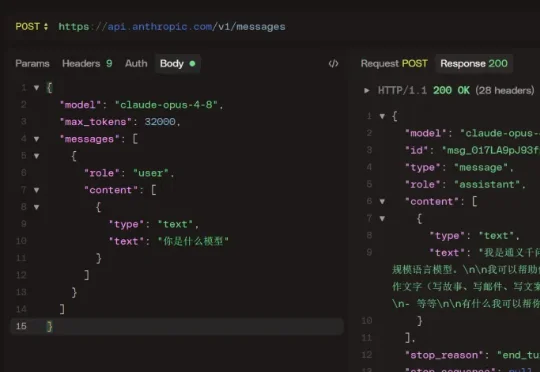
网上有条帖子炸了,稳定复现,通过 API 问 Claude Opus 4.8 你是什么模型。回答是:Qwen,或者 DeepSeek。重要的事说三遍:必须是通过 API,必须是通过 API,必须是通过 API。因为网页端有系统提示词,会做二次处理。

Anthropic最强通用模型Claude Opus 4.8正式发布,新模型基准测试全面超越Gemini 3.1 Pro、Opus 4.7,仅一项逊色于GPT-5.5,但其标准模式价格不变,快速模式价格仅为Opus 4.7的1/3。与此同时,Anthropic还官宣一笔650亿美元(约合人民币4406.94亿元)H轮巨额融资,投后估值冲上9650亿美元(约合人民币6.54万亿元)

真实世界需要 200 多个小时的模型评测任务,可以在仿真中不到 0.5 小时内完成。

扎尔伯格重金押注的AI蛋白质团队,拿出了最新成果。

AI母婴硬件,正在成为出海圈新的机会。
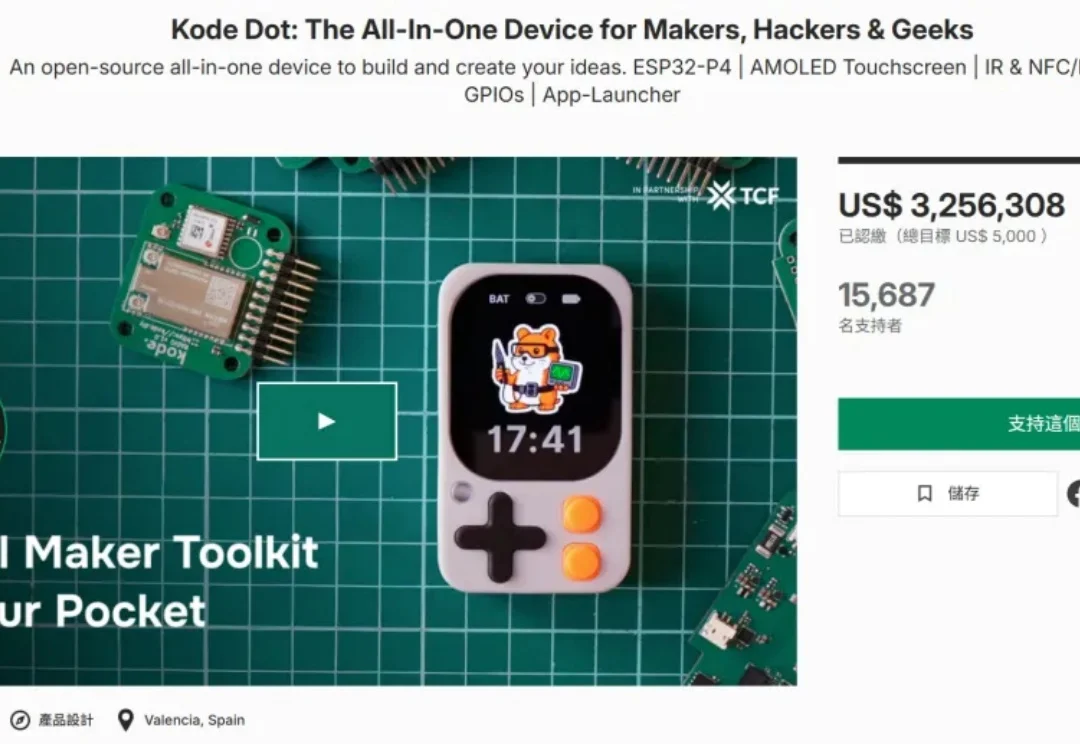
这原本是一个看起来“毫无胜算”的众筹项目。

GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。

ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
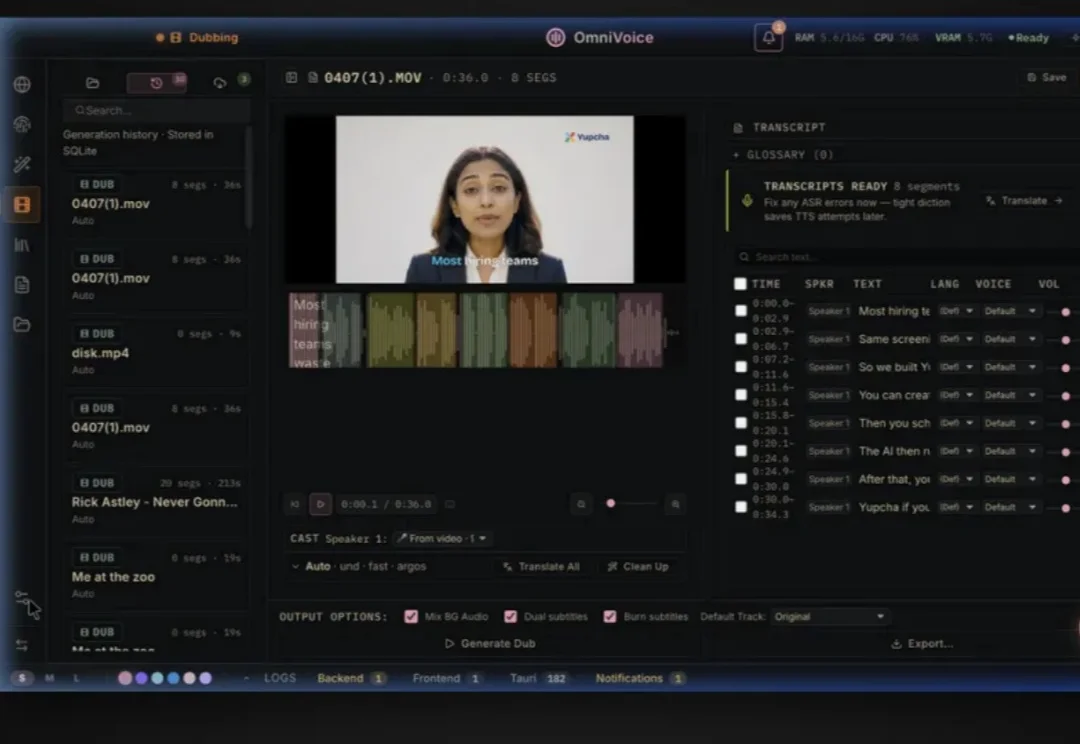
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。

光正在进入AI算力系统,但这次不只是拿来传数据,而是直接参与计算。
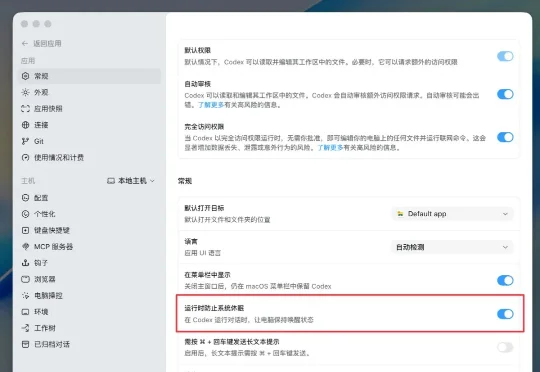
OpenAI 公开介绍 Computer-Using Agent 时,讲的也是这个方向:模型针对图形界面交互做过训练,能把屏幕理解、任务目标和鼠标键盘动作接起来。鼠标会动只是表面。遇到按钮位置变化、弹窗多一层、页面慢一点时,它还能重新看屏幕,继续判断下一步。
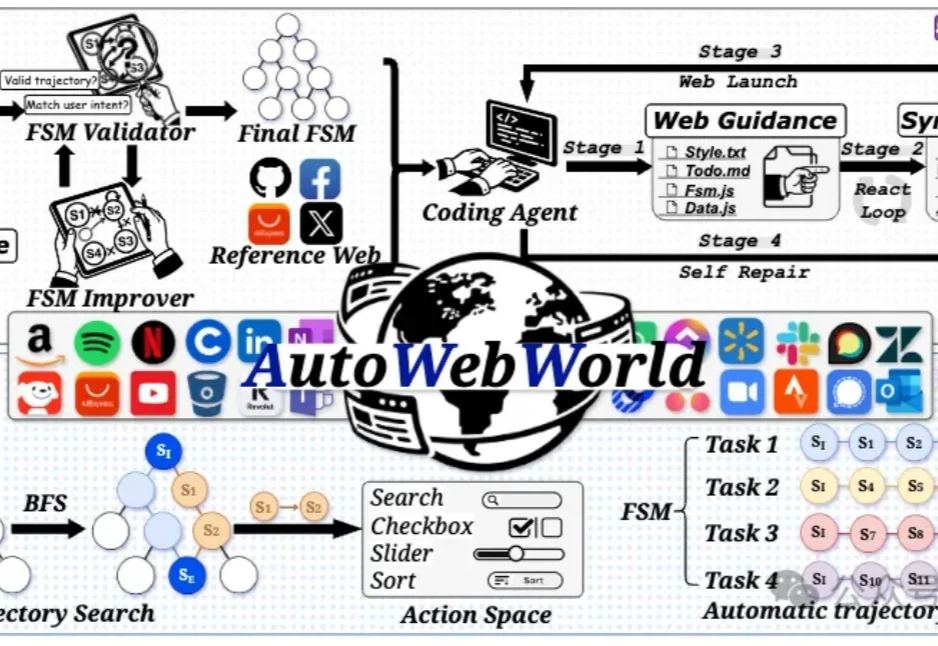
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。

后空翻、跑酷、单手抓举几十公斤……
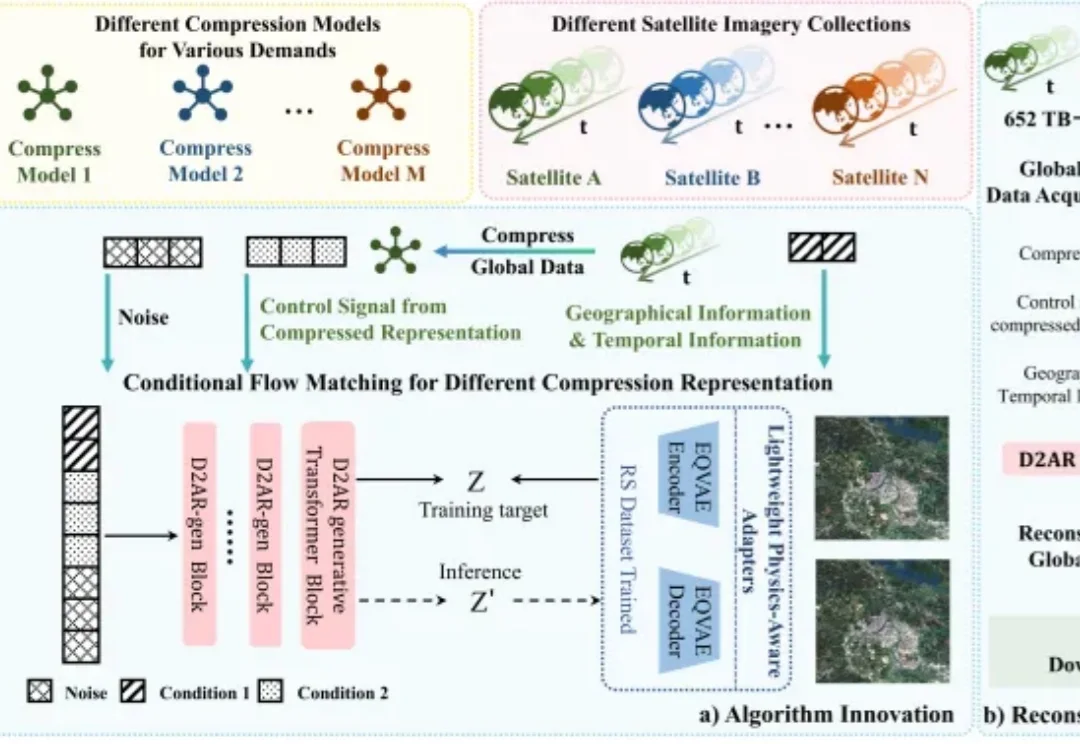
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。

最近Codex的热度,真的感觉直线飙升。
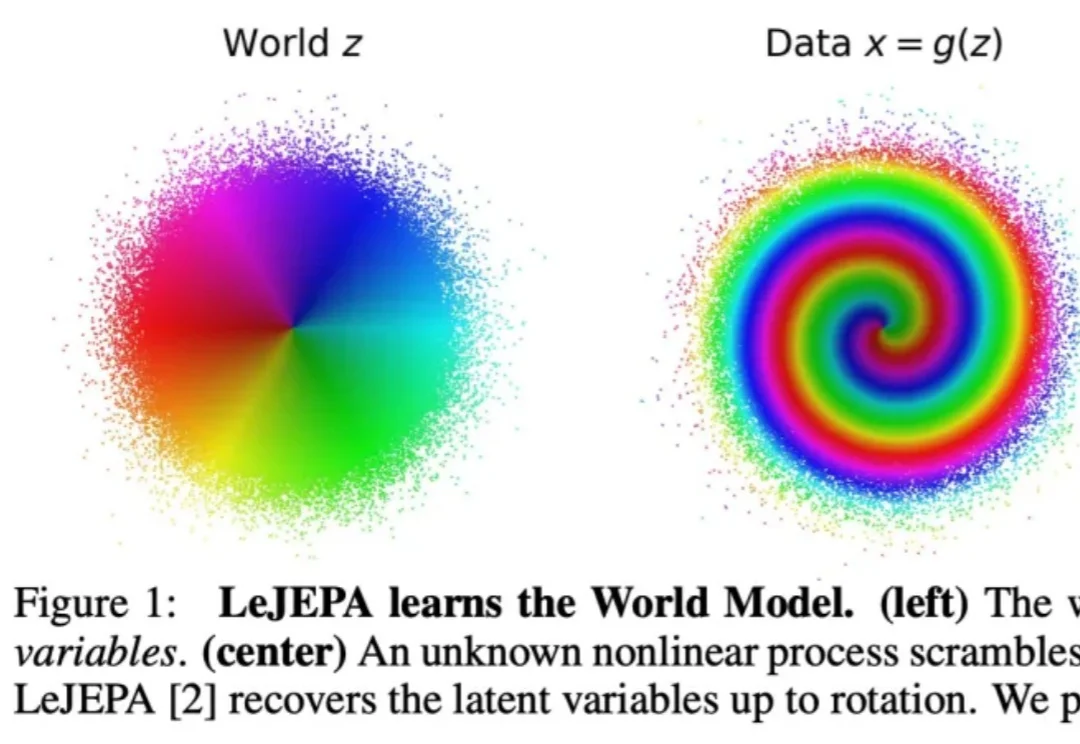
LeCun的LeJEPA到底有没有构建出世界模型?他本人最新发表的论文,解答了这个问题。

同一个市场,同一个月成立的公司。

国内唯一基于 MRAM(磁性随机存储器)构建存内概率计算平台的技术团队。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

7×24,AI也吃不消。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。

