


2025 AI巨头「全员恶人」:恩怨、爱恨与算计
2025 AI巨头「全员恶人」:恩怨、爱恨与算计OpenAI转身牵手AWS,苹果低头找谷歌续命,Meta开源翻车还内斗,马斯克直接把Macrohard挂上数据中心屋顶。2025年AI巨头们那些剪不断的纠葛。
来自主题:
AI资讯
10098 点击 2026-01-07 15:34
 搜索
搜索
OpenAI转身牵手AWS,苹果低头找谷歌续命,Meta开源翻车还内斗,马斯克直接把Macrohard挂上数据中心屋顶。2025年AI巨头们那些剪不断的纠葛。
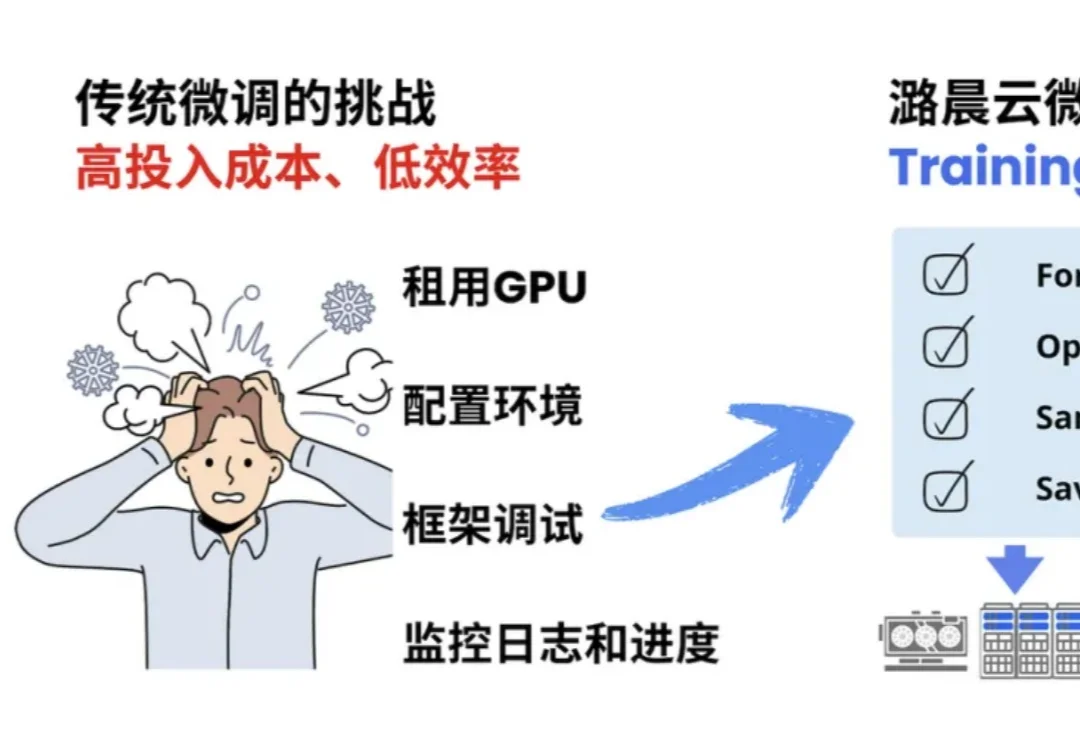
当 OpenAI 前 CTO Mira Murati 创立的 Thinking Machines Lab (TML) 用 Tinker 创新性的将大模型训练抽象成 forward backward,optimizer step 等⼀系列基本原语,分离了算法设计等部分与分布式训练基础设施关联,

根据《金融时报》报道,中国有关部门正在审查 Meta 以 20 亿美元收购 Manus 的交易,评估其是否违反技术出口管制规定。

今天,马斯克旗下AI创企xAI宣布,已经完成规模200亿美元(约合人民币1396.8亿元)的E轮融资。本轮融资获得超额认购,远远超过原定的150亿美元目标。xAI本轮融资的投资方阵容豪华。英伟达和思科作为战略投资方,将持续支持xAI快速扩展算力基础设施
2025 年 12 月 21 日,Steve Klabnik 迎来了他使用 Rust 的第十三个年头。作为 Rust 社区早期的核心人物之一,他在技术圈有着特殊的地位。在即将迈入 40 岁门槛之际,他在博客中坦言,过去几年过得颇为艰难,但现在的状态是「非常快乐」。

2025年,AI不再只是发布会上的炫技,也不再独属于工程师和资本。

一个百元级的「红灯」,如何成了信息焦虑时代的解药?

近日消息,在拉斯维加斯举行的 CES 2026 上,波士顿动力与谷歌 DeepMind 宣布达成一项全新的 AI 合作伙伴关系,旨在为人形机器人开启一个全新的人工智能时代。

2024年7月14日,2024年欧洲杯锦标赛冠军赛如期举行,比赛将决出欧洲最佳国家足球队。在比赛只剩下不到五分钟时,西班牙队和英格兰队比分为1比1平,此时西班牙球员Mikel Oyarzabal在禁区顶端扑球,踢进了看似制胜的一球[1]。然而,在这次进攻中,Oyarzabal的位置接近越位,或者说离球门太远。

想象一下,你正在训练一个未来的家庭机器人。你希望它能像人一样,轻松地叠好一件衬衫,整理杂乱的桌面,甚至系好一双鞋的鞋带。但最大的瓶颈是什么?不是算法,不是硬件,而是数据 —— 海量的、来自真实世界的、双手协同的、长程的、多模态的高质量数据。

年末,AI圈被一则重磅消息刷屏。
对于电子产品,我们已然习惯了「出厂即巅峰」的设定:开箱的那一刻往往就是性能的顶点,随后的每一天都在折旧。
这两年一直在关注 AI,Claude Code 给我带来的震撼,和当初 Nano Banana 在画图领域的革命,几乎是一个级别。
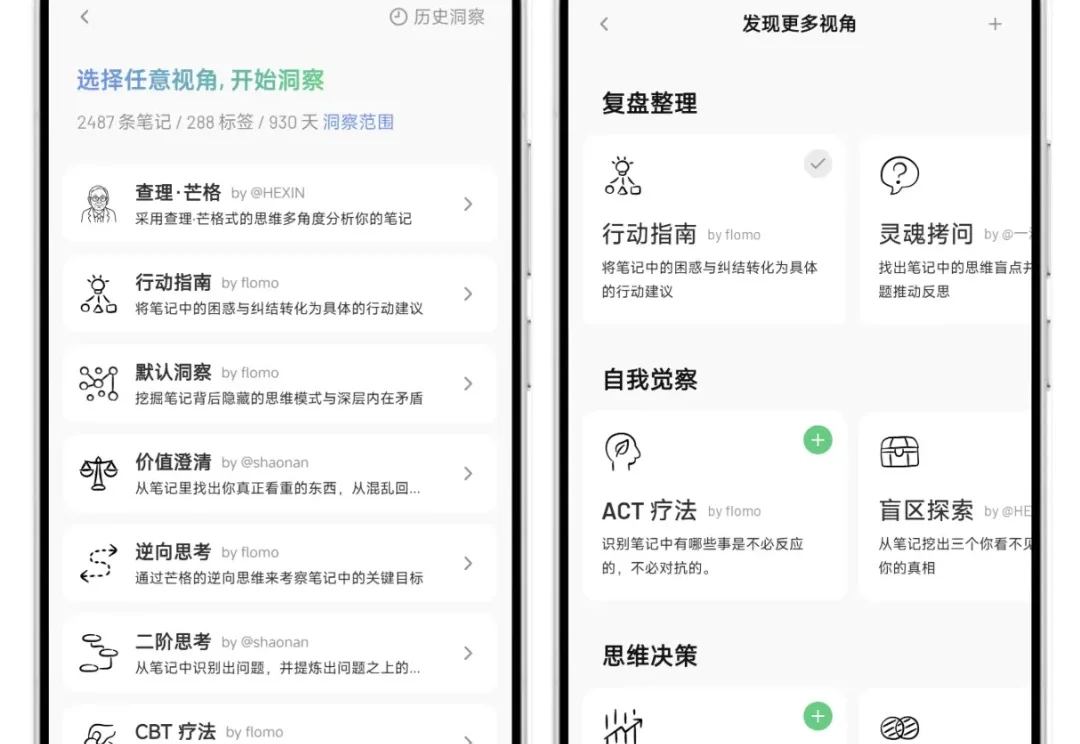
flomo 是我今年用过的应用里,少数真正把 AI 从「好玩」做到「好用」的产品。

2025 年,人工智能的发展重心正在发生一次根本性转移:从追求模型的规模,转向构建其理解与解决复杂现实问题的能力。在这一转型中,高质量数据正成为定义 AI 能力的新基石。作为人工智能数据服务的前沿探索者,数据堂深度参与并支撑着这场变革的每一个关键环节。本文将深入解读 2025 年 AI 五大技术趋势及其背后的数据需求变革。

现实世界不是 demo,人形机器人该如何进入真实世界?

2025 年,随着李飞飞等学者将 “空间智能”(Spatial Intelligence)推向聚光灯下,这一领域迅速成为了大模型竞逐的新高地。通用大模型和各类专家模型纷纷在诸多室内空间推理基准上刷新 SOTA,似乎 AI 在训练中已经更好地读懂了三维空间。

现在搞 AI 创作,最缺的其实不是模型,是耐心…为了做个像样的视频,活生生逼成了搬运工。

CES巨幕上,老黄的PPT已成中国AI的「封神榜」。DeepSeek与Kimi位列C位之时,算力新时代已至。
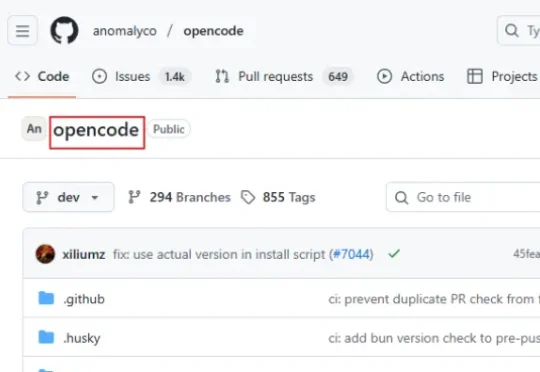
有没有一款工具,既有 Claude Code 那么强大的能力,又是完全开源免费的,还能让我自由选择用哪家的AI模型?答案是:有的!就是在GitHub上狂揽50.2K Star的新晋开源编程神器:OpenCode。
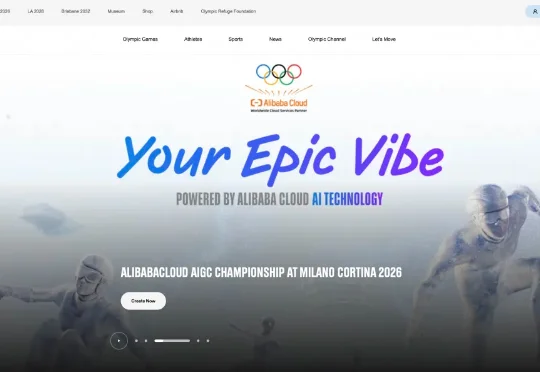
最近我还真看到一个有点不一样的的 AI 创作比赛,国际奥委会联合阿里云搞了一场「米兰冬奥会 AIGC 全球大赛」,用万相大模型输入一句话,生成 5 到 15 秒冬奥视频即可参赛。不需要专业设备、不需要懂技术、甚至不需要会滑雪,只需要有个脑洞。

英特尔发布年度旗舰AI PC芯片——第三代酷睿Ultra系列处理器(代号Panther Lake)。这是首款基于Intel 18A制程(1.8nm级)的计算平台,将AI PC引入埃米时代,端侧AI算力多达180TOPS。

她是当代人工智能界最具象征意义的女性科学家之一。提到人工智能领域,李飞飞(Fei-Fei Li)无疑是最醒目的那一个。1976年出生的她,早年在美求学,1999年以物理学荣誉学士毕业于普林斯顿大学,随后在加州理工学院获得电气工程博士学位。
新年刚至,陈天桥携手代季峰率先打响开源大模型的第一枪。

新年第一弹,OpenAI研发副总裁Jerry Tworek官宣离职,这位七年老兵给出的理由让人细思恐极:想做在OpenAI做不了的研究。从Dario Amodei出走创立Anthropic,到Ilya政变后离开,再到安全团队负责人摔门而出——OpenAI的核心大脑们正在以惊人的速度流失。

AMD公布未来两年芯片路线图。

文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。
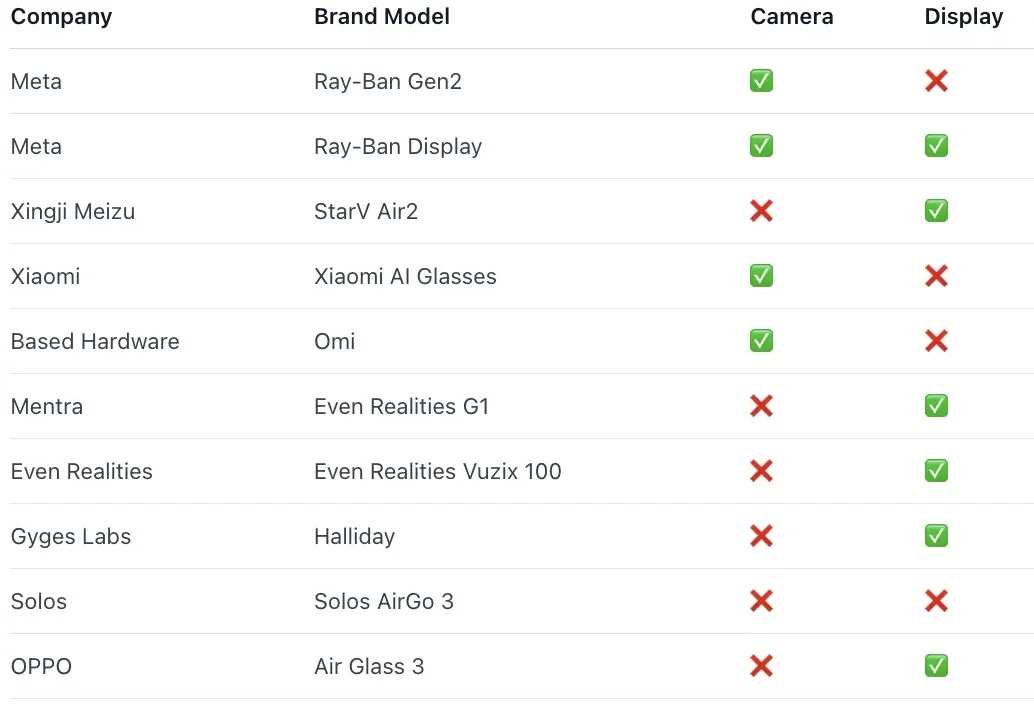
离了大谱了,AI真·走进了大学期末考场,并且还是以作弊者的身份。(你就说震不震惊吧)

专注于异构算力调度和虚拟化的 AI 初创企业上海密瓜智能科技有限公司(“密瓜智能”)已于近期完成数千万元的天使轮融资,本轮融资由复星创富领投,拙朴投资、种子投资人及产业方强力跟投。自去年 3 月获得超五百万元种子轮融资以来,密瓜智能在不足一年时间内已迅速完成 2 轮融资,展现出强劲的发展势能,其技术前景与商业价值备受市场认可。
「我们想解决的不是 『做 AI 工作流』,是『根本不需要有工作流』。所有要求用户『预先构建工作流』的 Agent 都是错的。」在 Agencize AI 产品发布之前,我们和张浩然聊了聊他对于生产力工具和工作流的看法,以及 Agencize AI 的真正竞争力。

