

a16z:2026 年的 AI 应用生态,关键问题是这几个
a16z:2026 年的 AI 应用生态,关键问题是这几个2026 年,基模会不会吃掉所有应用场景?
来自主题:
AI资讯
7297 点击 2026-01-09 11:45
 搜索
搜索
2026 年,基模会不会吃掉所有应用场景?

谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?最近,2025年底的一篇名为《LMArena is a cancer on AI》的文章被翻了出来。登上了Hacker News的首页,引起轩然大波!
今日,小米前高管王腾在个人微博发文透露创业新动态。据其所述,从小米离开后开始筹备创业,最近新公司已经成立,公司取名为“今日宜休”,目标是通过研发睡眠健康相关的产品。谈及入局“AI+健康睡眠”领域,王腾认为,新时代下AI大模型发展迅速,让很多产品的体验能大幅提升。

借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。

“我们只交付100%可以复现的轨迹。”

针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。

最近一年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

提起“AI战胜人类”,很多人第一反应是1997年IBM的“深蓝”击败国际象棋世界冠军卡斯帕罗夫。那场人机大战轰动全球,被视为人工智能的里程碑。

刚刚,MiniMax(0100.HK)正式登陆港交所上市,发行价为165港元(约合人民币147.9元),开盘价为235.4港元(约合人民币211.0元),较发行价上涨42.67%,目前已涨到270.8港元,总市值约为827亿港元。

抛开产品体验不谈的话,Rokid无疑是国内AR眼镜的先行者,他们用眼镜这个不可能三角最难平衡的硬件形态,硬是推出了10几个功能,客观上也推进了全产业链的发展。

在上期内容发布后 有很多小伙伴都反馈很好用 NotebookLM改不了细节?提示词 V2.0 生成既有质感,又能随意修改文字的完美 PPT

是你的、是我的、是每个人的黄金时代。

前端生态最具影响力的开源项目之一 Tailwind CSS,正经历一场罕见的生存压力测试。
10 年前,我人生第一次走进腾讯大厦的时候,无数次憧憬着可以和一群有趣的 Founder,出入在高端写字楼,有喝不完的咖啡,拿不完的年终奖和期权。但是现在我厌倦甚至讨厌这种精英主义的虚伪感,如今这些东西都有了,身处其中的人却在异化、在变得没那么快乐。

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
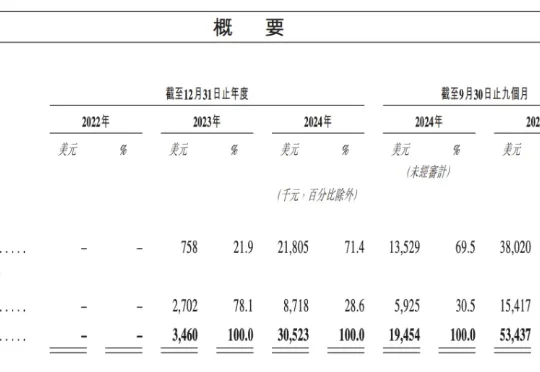
即将于 1 月 9 日敲钟上市的大模型公司 MiniMax,创下近年来港股 IPO 机构认购历史记录。此次参与 MiniMaxIPO 认购的机构超过 460 家,超额认购达 70 多倍。此前的认购记录属于宁德时代,其在 2025 年登陆港股市场时,剔除基石后超额认购 30 倍。

今年CES现场,一家来自中国深圳的公司,试图给出另一种明显更“落地”的解法。首次亮相CES的玄源科技(X-Origin),携两大品牌AIPi与Yonbo登场:从22美元起售的口袋型AI助手,到覆盖家庭与户外的儿童AI伙伴系统,这家公司用极低门槛、清晰边界

刚刚,谷歌母公司成为全球市值TOP 2,市值已达3.885万亿美元!在2026首个全球AI追踪报告中,Gemini的市场份额也在疯涨。被逼急的OpenAI,干脆甩出500亿美元的员工股票池,据说Ilya就分走了40亿。

CES 2026新AI硬件巡礼:中国团队抢眼,“深圳军团”把性价比打到新高度。智东西1月7日报道,在国际消费电子展CES 2026上,AI正在以更隐蔽、也更具体的方式进入硬件世界,一批新型AI硬件和创意展品刷足了存在感。
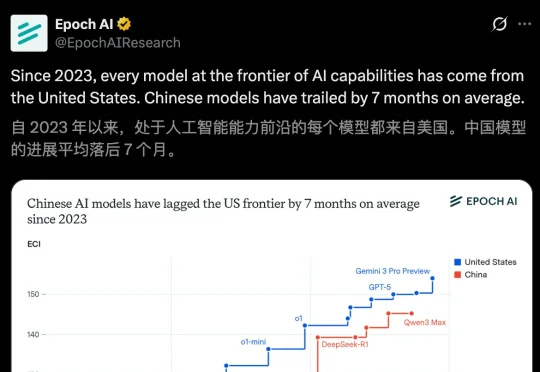
一张来自Epoch AI图表给出了一个冷静却尖锐的结论:中国AI平均落后7个月。一张图揭示真相:自2023年以来,前沿AI全部来自美国!最近,Epoch AI一份报告指出,中国AI模型的进展平均落后于美国7个月——最小差距为4个月,最大差距为14个月。
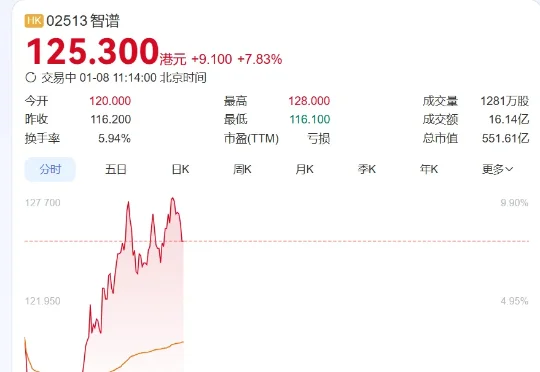
1月8日,大模型六小龙第一股,智谱上市了,市值直超551亿港元,而且一路涨幅超已逾7%。而就在上市前一天,小编注意到,智谱创立发起人兼首席科学家唐杰在微博上发布了一条充满预告意味的帖子,称:“AA(artificialanalysis)换了几个benchmark,基本是把原来刷爆的都换了,现在评估越来越难,新增加的Physical Reasoning貌似还很难。。。。”

“99%的企业级 Agent 都只是玩具!”
在人工智能飞速发展的今天,我们的社交媒体动态似乎被精心净化,然而在这光鲜背后,一支隐形的全球劳动力正默默承受着难以言喻的创伤。
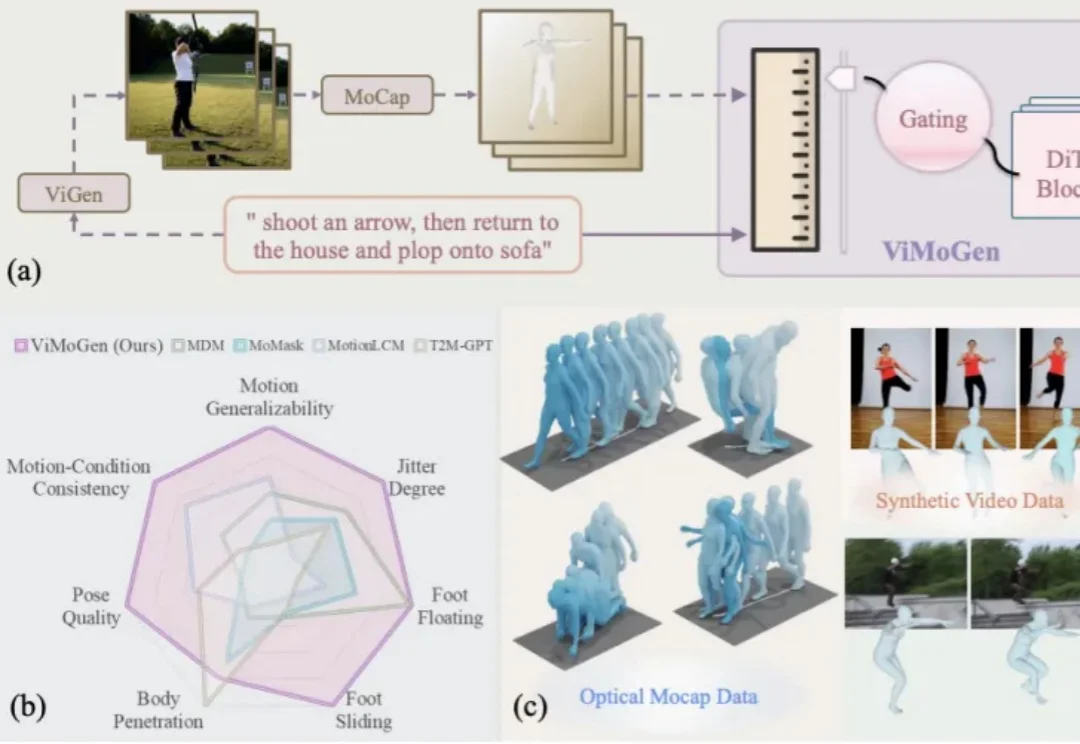
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。
Manus 卖给 Meta 这事儿,最近闹得沸沸扬扬。
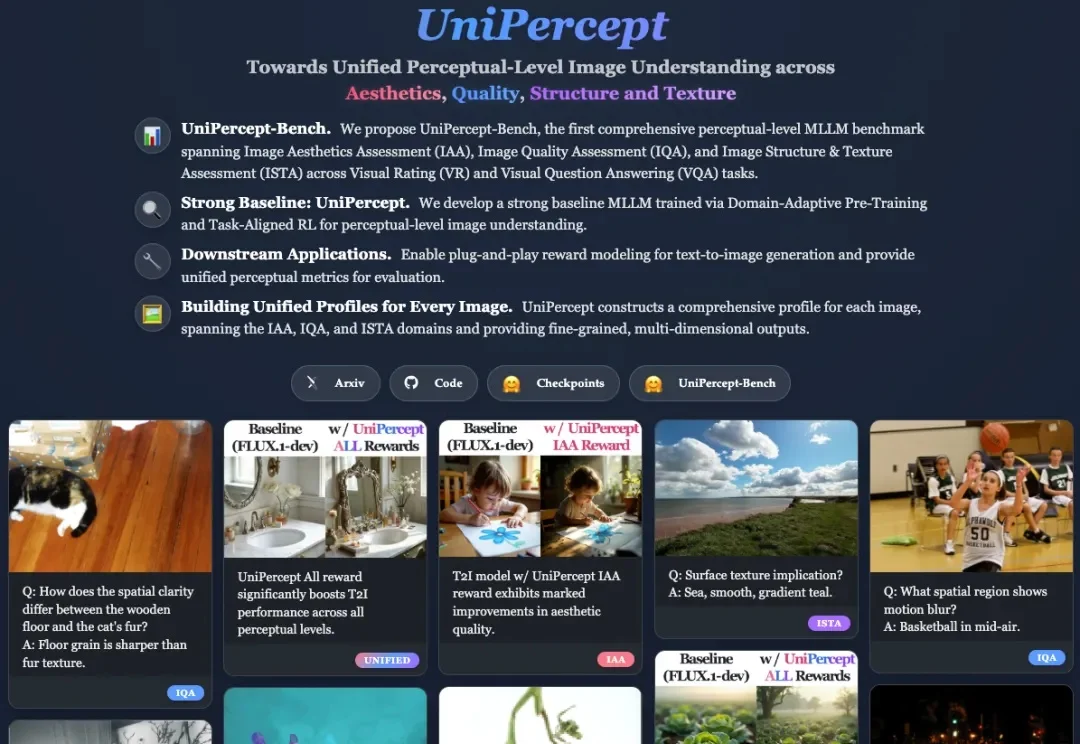
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。

本文为《2025 年度盘点与趋势洞察》系列内容之一,由 InfoQ 技术编辑组策划。本系列覆盖大模型、Agent、具身智能、AI Native 开发范式、AI 工具链与开发、AI+ 传统行业等方向,通过长期跟踪、与业内专家深度访谈等方式,对重点领域进行关键技术进展、核心事件和产业趋势的洞察盘点。

之前刷到个帖子,提到有部讲述中国高铁发展的纪录片,用了AI生成的画面。这部纪录片是系列节目中的一集,有争议的画面展示了一段架梁作业的过程。整个画面AI味十足,也不符合实际情况。
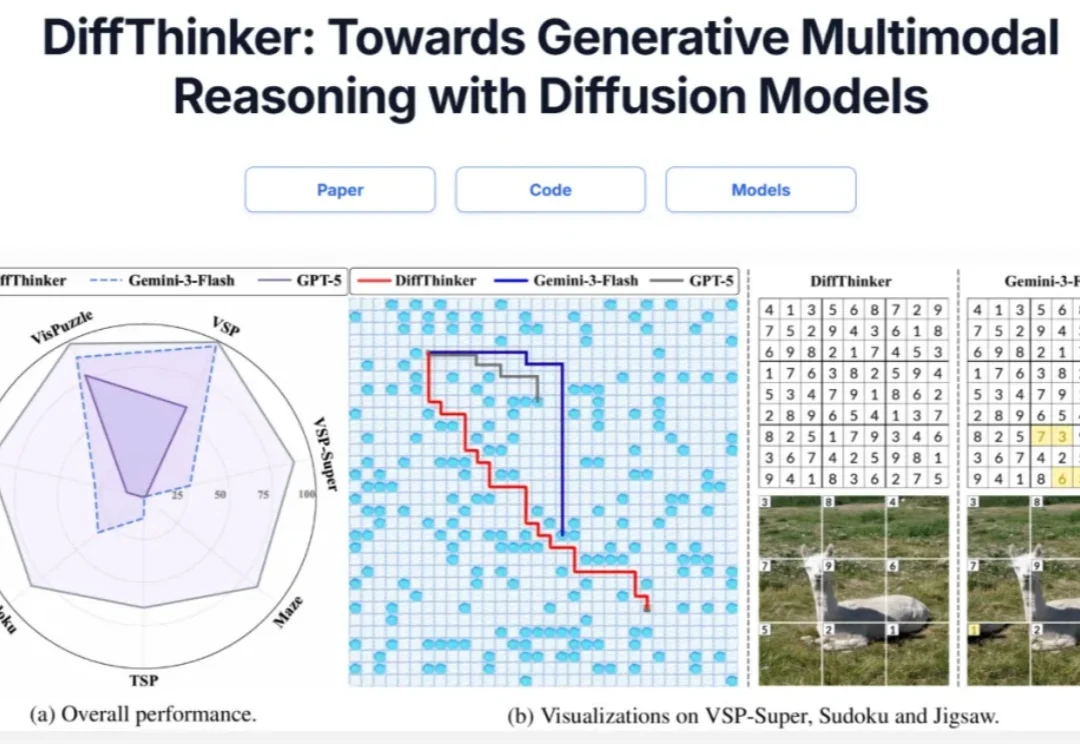
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
两天前,DeepSeek悄无声息地把R1的论文更新了,从原来22页「膨胀」到86页。DeepSeek向世界证明:开源不仅能追平闭源,还能教闭源做事!

