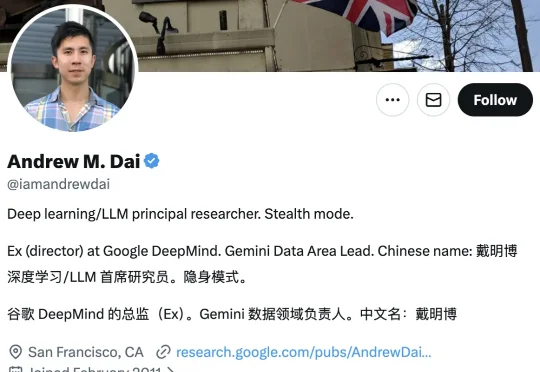
在谷歌深耕14年,华人研究员创立视觉AI公司Elorian,计划融资5000万美元
在谷歌深耕14年,华人研究员创立视觉AI公司Elorian,计划融资5000万美元戴明博表示,这家名为 Elorian 的新公司目前正在与投资人洽谈,计划完成一轮约 5000 万美元的种子融资。知情人士透露,由前 CRV 普通合伙人 Max Gazor 于去年 10 月创立的风投机构 Striker Venture Partners 正在洽谈领投该轮融资。
来自主题:
AI资讯
9507 点击 2026-01-11 10:38